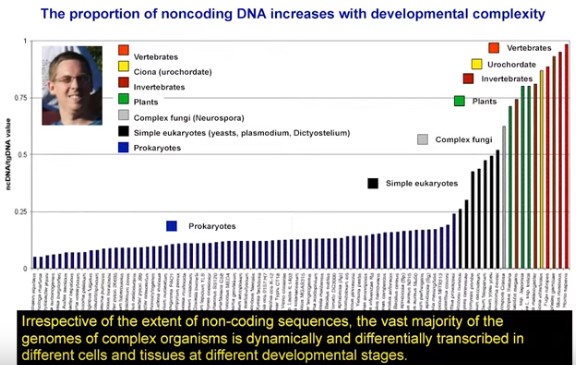
The authors of a recent paper think we need a new term "spam DNA" to describe some features of the human genome.
Fagundes, N.J., Bisso-Machado, R., Figueiredo, P.I., Varal, M. and Zani, A.L. (2022) What We Talk About When We Talk About “Junk DNA”. Genome Biology and Evolution 14:evac055. [doi: 10.1093/gbe/evac055]
“Junk DNA” is a popular yet controversial concept that states that organisms carry in their genomes DNA that has no positive impact on their fitness. Nonetheless, biochemical functions have been identified for an increasing fraction of DNA elements traditionally seen as “Junk DNA”. These findings have been interpreted as fundamentally undermining the “Junk DNA” concept. Here, we reinforce previous arguments that this interpretation relies on an inadequate concept of biological function that does not consider the selected effect of a given genomic structure, which is central to the “Junk DNA” concept. Next, we suggest that another (though ignored) confounding factor is that the discussion about biological functions includes two different dimensions: a horizontal, ecological dimension that reflects how a given genomic element affects fitness in a specific time, and a vertical, temporal dimension that reflects how a given genomic element persisted along time. We suggest that “Junk DNA” should be used exclusively relative to the horizontal dimension, while for the vertical dimension, we propose a new term, “Spam DNA”, that reflects the fact that a given genomic element may persist in the genome even if not selected for on their origin. Importantly, these concepts are complementary. An element can be both “Spam DNA” and “Junk DNA”, and “Spam DNA” can also be recruited to perform evolved biological functions, as illustrated in processes of exaptation or constructive neutral evolution.

The authors are scientists at the Federal Univesity of Rio Grande do Sul in Brazil. They are concerened about the origins of junk DNA and whether true selected effect functions (strong selected effect = SSE) conflict with the definition of junk DNA. Here's how they put it,
Paradoxically as it may seem, under the SSE definition, elements that contribute positively to fitness and are maintained by purifying selection would still count as “junk” only because they did not originate as an adaptation.
This is essentially correct according to how many philosophers define selected effect functions but that issue was resolved by focusing on purifying selection as the important criterion and ignoring the history of the trait (= maintenance function, MF). There is only a 'paradox' if you stick to the philosophy definition of function (i.e. SSE) and even then, the paradox only exists if the SSE definition is the only way to identify junk DNA. [see: The Function Wars Part IX: Stefan Linquist on Causal Role vs Selected Effect] The authors recognize this since they include a good discussion of this other definition (MF) and its advantages. Nevertheless, they propose a new term called "spam DNA" to help clarify the problem.
"Spam DNA" represents every genomic element which has not been selected for during its origin in the genome, even if it currently participates in relevant biological functions.
All of the DNA in the light blue box is spam DNA. Note that it includes DNA that is currently functional as long as it originated from junk DNA as they define it. Also, some junk DNA isn't spam DNA as long as it arose from the inactivation of DNA that used to have a function. Thus, pseudogenes aren't junk and neither are bits and pieces of transposons.
This isn't helpful. The current debate is about how much of our genome is junk so who cares about the history of individual sequences? A significant amount of what we currently define as junk DNA may have come from once-active transposons but we may never be able to trace the history of each piece of junk DNA. Does it fall into the first category in the figure (functional to junk) or is it spam DNA? Is this really important? No,it is not.
Function Wars(My personal view of the meaning of function is described at the end of Part V.)
- On the Meaning of the Word "Function"
- The Function Wars: Part I
- The Function Wars: Part II
- The Function Wars: Part III
- The Function Wars: Part IV
- Restarting the function wars (The Function Wars Part V)
- The Function Wars Part VI: The problem with selected effect function
- The Function Wars Part VII: Function monism vs function pluralism
- The Function Wars Part VIII: Selected effect function and de novo genes
- The Function Wars Part IX: Stefan Linquist on Causal Role vs Selected Effect
- The Function Wars Part X: "Spam DNA"?