Transposable Elements: (44% junk)
DNA transposons:
active (functional): <0.1%
defective (nonfunctional): 3%
retrotransposons:
active (functional): <0.1%
defective transposons
(full-length, nonfunctional): 8%
L1 LINES (fragments, nonfunctional): 16%
other LINES: 4%
SINES (small pseudogene fragments): 13%
co-opted transposons/fragments: <0.1% a
aCo-opted transposons and transposon fragments are those that have secondarily acquired a new function.Viruses (9% junk)
DNA viruses
active (functional): <0.1%
defective DNA viruses: ~1%
RNA viruses
active (functional): <0.1%
defective (nonfunctional): 8%
co-opted RNA viruses: <0.1% b
bCo-opted RNA viruses are defective integrated virus genomes that have secondarily acquired a new function.Pseudogenes (1.2% junk)
(from protein-encoding genes): 1.2% junk
co-opted pseudogenes: <0.1% c
cCo-opted pseudogenes are formerly defective pseudogenes those that have secondarily acquired a new function.Ribosomal RNA genes:
essential 0.22%
junk 0.19%
Other RNA encoding genes
tRNA genes: <0.1% (essential)
known small RNA genes: <0.1% (essential)
putative regulatory RNAs: ~2% (essential) Protein-encoding genes: (9.6% junk)
transcribed region:
essential 1.8%
intron junk (not included above) 9.6% d
dIntrons sequences account for about 30% of the genome. Most of these sequences qualify as junk but they are littered with defective transposable elements that are already included in the calculation of junk DNA.Regulatory sequences:
essential 0.6%
Origins of DNA replication
<0.1% (essential) Scaffold attachment regions (SARS)
<0.1% (essential) Highly Repetitive DNA (1% junk)
α-satellite DNA (centromeres)
essential 2.0%
non-essential 1.0%%
telomeres
essential (less than 1000 kb, insignificant)
Intergenic DNA (not included above)
conserved 2% (essential)
non-conserved 26.3% (unknown but probably junk)
Total Essential/Functional (so far) = 8.7%
Total Junk (so far) = 65%
Unknown (probably mostly junk) = 26.3%
For references and further information click on the "Genomes & Junk DNA" link in the box
LAST UPDATE: May 10, 2011 (fixed totals, and ribosomal RNA calculations)
 November 11, 2006
November 11, 2006Sea Urchin Genome Sequenced
The sea urchin genome is 814,000 kb or about 1/4 the size of a typical mammalian genome. Like mammalian genomes, the sea urchin genome contains a lot of junk DNA, especially repetitive DNA. The preliminary count of the number of genes is 23,300. This is about the same number that we have in our genomes. Only about 10,000 of these genes have been annotated by the sea urchin sequencing team.
November 19, 2006
Neanderthal genome FAQ
I've hesitated to comment about the sequencing of Neanderthal DNA 'cause I haven't read the papers. Fortunately John Hawks has made the effort and posted the Neandertal genome FAQ. It should answer all your questions, except why John Hawks calls them "Neandertal" when Science and Nature use "Neanderthal." Personally, I prefer the original "Neanderthal."
 December 21, 2006
December 21, 2006Mammalian Gene Families: Humans and Chimps Differ by 6%
By scanning the available genome sequences, Demuth et al. were able to cluster all genes into 15,389 groups called "gene families." Of these, 3,114 were single genes confined to a single species. These were presumed to be annotation artifacts and were discarded. Not all of the remaining groups were present in all five species. A total of 2,285 additional groups were confined to distinct lineages on the mammalian tree indicating that they had been "created" after divergence from the common ancestor. This leaves 9,990 groups that were probably present in the ancestor of dog, human, chimp, mouse, and rat.
The question is, how many of these gene families show gain or loss of numbers during mammalian evolution? The answer is 5,622 or 56.3% (5622/9,990).
February 12, 2007
Junk DNA: Scientific American Gets It Wrong (again)
In "Ask the Experts" somebody asked What is junk DNA, and what is it worth?. The question was answered by "expert" Wojciech Makalowski of Pennsylvania State University. Here's the answer ...
In 1972 the late geneticist Susumu Ohno coined the term "junk DNA" to describe all noncoding sections of a genome, most of which consist of repeated segments scattered randomly throughout the genome.This is very misleading.
 March 13, 2007
March 13, 2007Genome Size in Birds
One of the things that Gregory works on is the correlation between cell size and genome size. It turns out that the size of the nucleus is related to the size of the cell, such that large genomes give rise to large nuclei and large cells. This is particularly evident when you look at red blood cells and Gregory has a remarkable image showing this correlation on his website [Gregory Lab].
It has been known for some time that birds have smaller genomes than reptiles and mammals. This has natually given rise to an adaptionist explanation;namely, that the small genome is due to selection for small cells in birds because they exert a lot of energy in flight. In other words, small genomes are an adaption for flight.
 March 19, 2007
March 19, 2007Facts and Myths Concerning the Historical Estimates of the Number of Genes in the Human Genome
The graphic above was taken from the Genesweep lottery. This is the betting that Asp refers to. It shows the range of gene number estimates by scientists who were involved in genome sequencing projects. Note that there are many estimates in the 40-50,000 range and a fair number below 40,000. The point is obvious—lots of experts anticipated fewer than 50,000 genes in the human genome (see The nature of the number. Nature Genetics 25:127 (2000)).
March 23, 2007
 How Many Genes Do We Have?
How Many Genes Do We Have?The number of genes in the human genome flutuates on a monthly basis as the genome annotators add new genes and remove false positives. It's an ongoing process that's not likely to be complete in the near future.
March 21, 2007
Summary of Genes on Human Chromosomes
I've prepared a table of the number and types of gene on each human chromosome based on the data at the Ensembl site managed by the Wellcome Trust Sanger Institute in Cambridge UK.
The total number of genes comes to 26,290.
 April 13, 2007
April 13, 2007Testing the Macaque Genome
We've already been looking at the macaque genome for several months but now that the genome paper is being published I thought some of you might be interested in how the preliminary data stacks up to what we expect.
April 29, 2007
Noncoding DNA and Junk DNA
The author of the Scientific American article, JR Minkle, has responded on the Scientific American website [The DNA Formerly Known as Junk]. Minkle is a science writer who has covered a lot of stories in many different fields. As far as I know Minkle has not written very much about biology before summarizing the work in the PNAS paper. There was a time when all the science in that journal was written by scientists who were experts in the field [The Demise of Scientific American]. Anyway, that's not the main point here. JR Minkle has listened to the critics and made a decision to avoid the term "junk DNA" from now on.
That's a bad decision.
 May 25, 2007
May 25, 2007SCIENCE Questions: Why Do Humans Have So Few Genes?
Elizabeth Pennisi is a news writer for Science magazine. She has been publishing articles there for at least ten years. She had previously written about genes and genomes, including earlier articles about the number of genes in the human genome.
Pennisi begins with the usual mythology about how surprised scientist were to discover that humans had fewer than 30,000 genes [see Facts and Myths Concerning the Historical Estimates of the Number of Genes in the Human Genome]. She continues by using most of the standard excuses for the Deflated Ego Problem [The Deflated Ego Problem].
 May 24, 2007
May 24, 2007The Deflated Ego Problem
The human chauvinists are disappointed that our genome isn't as complex as our brains and behavior suggest (to them). They expected to see tangible evidence that humans were at the top of the heap. I call this "The Deflated Ego Problem." The question before us is whether this is a real scientific problem or whether it stems from an incorrect understanding of evolution and development.
Having barely survived a major blow to their ego when the human genome turned out to have fewer than 30,000 genes, the deflated ones have fought back with various schemes to explain the "paradox." What they look for is some special mechanism that we humans possess in order to get a bigger bang for our buck. In other words, they're looking for their missing complexity in other places.
 June 13, 2007
June 13, 2007WIRED on Junk DNA
Junk DNA is the DNA in your genome that has no function. Much of it accumulates mutations in a pattern that's consistent with random genetic drift implying strongly that the sequences in junk DNA are unimportant. In fact, the high frequency of sequence change (mutation plus fixation) is one of the most powerful bits of evidence for lack of function.
June 14, 2007
Catherine Shaffer Responds to My Comments About Her WIRED Article
Catherine Shaffer says,
I interviewed five scientists for this article. Dr. Francis Collins, Dr. Michael Behe, Dr. Steve Meyers, Dr. T. Ryan Gregory, and Dr. Gill Bejerano. Each one is a gentleman and a credentialed expert either in biology or genetics. I am grateful to all of them for their time and kindness.
 June 19, 2007
June 19, 2007What is a gene, post-ENCODE?
My initial impression is that they have failed to demonstrate that the rare transcripts of junk DNA are anything other than artifacts or accidents. It's still an open question as far as I'm concerned.
It's not an open question as far as the members of the ENCODE Project are concerned and that brings us to the new definition of a gene.
July 8, 2007
Stop the Press!!! ... Genes Have Regulatory Sequences!
Ira Flatow interviews John Greally (see photo) on Science Friday. Greally talks about the ENCODE project and junk DNA. You might be surprised to learn that the expression of genes is controlled by ... wait for it ... REGULATORY SEQUENCES! According to Greally the discovery of these regulatory sequences reveals that junk DNA isn't junk at all.
July 24, 2007
Junk DNA in New Scientist
I just got my copy of the July 14th issue of New Scientist so I can comment on the article Why 'junk DNA' may be useful after all by Aria Pearson. RPM at evolvgen thinks it's pretty good [Junk on Junk] and so does Ryan Gregory at Genomicron New Scientist gets it right]. I agree. It's one of the best articles on the subject that I've seen in a long time.
 September 5, 2007
September 5, 2007The Role of Ultraconserved Non-Coding Elements in Mammalian Genomes
Ahituv et al. then deleted the four ultraconserved sequences from the mouse genome using standard knockout technology. Mice that were homozygous for the knockouts showed no evidence of any defect compared to wild-type mice. In other words, the ultraconserved elements seemed to be completely dispensable—a result that is not consistent with their extreme conservation.
September 07, 2007
Adaptive Evolution of Conserved Noncoding Elements in Mammals
"Adaptive Evolution of Conserved Noncoding Elements in Mammals" is the title of a paper that's just been published in PLoS Genetics [Kim and Pritchard (2007)].
With a title like that you'd think the paper would be really interesting because conserved noncoding elements are a hot topic. Recall that these are short sequences in the genomes of diverse mammals that are highly similar. They were thought to be examples of regulatory sequences but deleting them from the mouse genome seems to have no effect [The Role of Ultraconserved Non-Coding Elements in Mammalian Genomes]. It's a little puzzling to see "adaptive evolution" in the title since the very fact that these short sequences are conserved implies adaptation.
 September 14, 2007
September 14, 2007Genome Size, Complexity, and the C-Value Paradox
Forty years ago it was thought that the amount of DNA in a genome correlated with the complexity of an organism. Back then, you often saw graphs like the one on the left. The idea was that the more complex the species the more genes it needed. Preliminary data seemed to confirm this idea.
October 7, 2007
Retrotranspsons
RNA viruses are viruses that contain RNA instead of DNA. When the RNA molecule is injected into the cell it serves immediately as a template for translation. All RNA viruses have a genes for making new viral particles and new copies of the RNA genome.
In eukaryotes, there is a large class of RNA viruses known as retroviruses. They have an obligatory stage where the RNA is reverse transcribed into DNA and the DNA is inserted into the genome where it resides as a provirus.

October 7, 2007
Junk in your Genome: LINEs
About 17% of your genome is composed of L1 LINEs and fragments. It is one of the major sources of junk DNA in your genome.
October 11, 2007
Junk RNA
There are a lot of studies suggesting that a substantial percentage of the genome is transcribed even though less than 5% is known to be functional. This leads to the idea that it encodes some unknown function. The argument is that these regions would not be transcribed unless they were doing something useful.
One objection to these studies is that the workers are looking at artifacts. The so-called transcripts are just noise from accidental transcription. This ties in with the idea that the EST database is full of examples of "transcripts" that don't make any biological sense.
 October 12, 2007
October 12, 2007The Genome of Chlamydomonas reinhardtii
The nuclear genome is 121 Mb (121,000,000 base pairs) in size and it's divided into 17 linkage groups (chromosomes). This is a draft genome sequence representing about 95% of the complete sequence with 13x coverage of the sequenced regions. The remaining 5% consists mostly of repeat regions and it's unlikely that they will ever be sequenced.
The preliminary analysis predicts 15,143 protein-encoding genes; three ribosomal RNA clusters; and 259 transfer RNA genes (tRNA).
November 19, 2007
Crystal Tells Us about the Human Genome
This is a video about the human genome. Crystal tells us lots of interesting things about the size of our genome, number of genes, junk DNA, whether the DNA of different races is the same etc. etc.
It makes my blood boil.
November 21, 2007
Bacteria Genomes Are Degrading
At one point in his talk last night Kirk Durston mentioned the bacterial flagella. He acknowledged that the "Darwinists" have proposed an evolutionary pathway from a Type III secretory structure to flagella.
This pathway is improbable, according to Durston, because flagella are more complicated than secretory pores so flagella have to evolve first.
What? Yes, that's right. Scientists have now shown that the most primitive bacteria were very complex and evolution has been all downhill from then on.
November 21, 2007
Bacterial Genomes and Evolution
Ryan Gregory is one of the world's leading experts on genomes and their evolution. He's also a Professor at the University of Guelph. Ryan has published an excellent description of what the Mira et al. (2000) paper shows and what it does not show. You should all read it [Bacterial genomes and evolution].
For Kirk Durston's sake, I hope Ryan Gregory isn't on his Ph.D. oral committee.
 November 29, 2007
November 29, 2007More Misconceptions About Junk DNA
Lots of scientists use the term "junk DNA." Properly, understood, it's a very useful term and has been for several decades [Noncoding DNA and Junk DNA].
Yes, it's true that journalists often don't understand junk DNA and they are easily tricked into thinking that junk DNA is a discredited concept. The journalists are wrong, not the scientists who use the term.
December 4, 2007
TR Gregory on Junk DNA
Ryan Gregory has posted another interesting discussion about junk DNA [Genome size, code bloat, and proof-by-analogy.]. You should read the entire article but I want to comment briefly on two important points.
December 8, 2007
Junk DNA in the Toronto Star
Cameron Smith writes,
To find answers, molecular biologists had to revise their notions of the genetic code. They knew that a huge number of genes in the human genome, making up more than 98 per cent of the genome, don't code protein. These they had previously dismissed as evolutionary leftovers, or junk DNA.
In an enormous turnaround, they began looking at these non-coding genes more closely and discovered they were not junk after all.
December 11, 2007
Stop the Press - Genes Have Regulatory Sequences!
You heard it here first—well, not exactly. The breaking news was first reported over at Biology News Net. Junk DNA isn't junk at all because it's full of regulatory regions controlling gene expression. This is excuse #5 of The Deflated Ego Problem.
 December 27, 2007
December 27, 2007The Grapevine Genome
The genome has 19 chromosomes amounting to 487 Mb of DNA (487 × 106 base pairs). This is comparable in size to the three other plant genomes that have been sequenced; rice, poplar, and Arabidopsis.
The published sequence is referred to as a "high-quality draft" by the authors. They report 30,434 protein-encoding genes and 600 tRNA genes.
December 28, 2007
The Second Grapevine Genome Is Published
The genome size is 505 Mb (505 × 106 bp). This is larger than the earlier published sequence (487 Mb). The extra DNA is almost entirely due to inclusion of ribosomal RNA clusters. Velasco et al. (2007) identified 29,585 genes—only slightly fewer than the 30,434 genes reported by Jaillon et al. (2007). Both teams used fairly strict criteria for identifying and annotating genes.
 January 13, 2008
January 13, 2008How Much Junk in the Human Genome?
Ryan Gregory has another contribution to this question that's well worth a read [Is most of the human genome functional?].
Among other things, Ryan picks on the views of John Mattick who has got to be one of the worst scientists in the field. Whenever I read a paper by Mattick I revise my opinion of the value of peer-reviewed literature. It's bad enough that Mattick has silly ideas but it's even sadder that his "peer" reviewers don't recognize it.
January 15, 2008
Humans Have Only 20,500 Protein-Encoding Genes
This analysis was extended to the other gene catalogs (Vega, and RefSeq) as well as an updated version of the Ensembl catalog (v38). This resulted identification of an additional 1271 valid genes. Adding in the genes in the mitochondrial genome (13) and the Y chromosome (78) gives a total of 20,470 genes.
January 15, 2008
Greg Laden Gets Suckered by John Mattick
Here's what Greg says [Genes are only part of the story: ncRNA does stuff].The "Junk DNA" story is largely a myth, as you probably already know. DNA does not have to code for one of the few tens of thousands of proteins or enzymes known for any given animal, for example, to have a function. We know that. But we actually don't know a lot more than that, or more exactly, there is not a widely accepted dogma for the role of "non-coding DNA." It does really seem that scientists assumed for too long that there was no function in the DNA.
January 17, 2008
A Junk DNA Quiz
Take the junk DNA quiz in the left sidebar to let me know what you think of your genome. How much of it could be removed without affecting our species in any significant1 way in terms of viability and reproduction? Or even in terms of significant ability to evolve in the future? In other words, how much is junk?
 January 18, 2008
January 18, 2008Soybean Genome
A preliminary draft of the soybean (Glycine max) genome has been released on the Phytozome website [Glycine max Genome].
The reported size of the genome is 950 Mb (950 × 106 base pairs). This is considerably larger that the genomes of grape (505 Mb), Arabidopsis (157 Mb), rice (389 Mb), and polar (485 Mb).
January 23, 2008
Ribosomal RNA Genes in Eukaryotes
The "genes" for ribosomal RNAs in eukaryotic genomes are found in separate clusters. One cluster consists of hundreds of copies of the 5S gene. These genes are transcribed by RNA polymerase III [Eukaryotic RNA Polymerases].
The other ribosomal RNA genes are found in an "operon"-like structure that's similar to the bacerial operons [Ribosomal RNA Genes in Bacteria]. Unlike bacterial transcription units, these ones are found in large tandem arrays on eukaryotic chromosomes. There can be hundreds of individual transcription units in a cluster and there can be several clusters. In humans, for example there are five clusters on five different chromosomes and each one has between 50 and 100 transcription units. The large eukaryotic ribosomal RNA genes are transcribed by RNA polymerase I.
 January 28, 2008
January 28, 2008Junk DNA Poll
Just a reminder to vote in the junk DNA poll seen in the left sidebar. Check out A Junk DNA Quiz and comments for more information.
January 31, 2008
Results of Junk DNA Poll
The results are surprising to me. I would have thought that a far higher percentage would have voted for 50% or more. As it turns out, half of you think that 50% of our genome is essential. That's not right.
 February 1, 2008
February 1, 2008Human Ribosomal RNA Genes
Total ribosomal RNA genes in the genome:
5S: 100 copies of 2.2 kb repeats = 220 kb. (estimate 100 kb essential, 120 kb junk)
45S: 98 copies of 43 kb repeats = 4214 kb. (estimate 1500 kb essential, 2714 junk)
February 7, 2008
Junk in Your Genome: SINES
Today I want to discuss Short Interspersed Elements or SINEs. These pieces of DNA tend to be only 100-400 bp in length but they contain all the features of transposons at their ends. The most important of these features is a short repeat of genomic DNA.
February 7, 2008
Junk in Your Genome: Pseudogenes
Pseudogenes are non-functional DNA sequences that resemble genes. Much of the DNA related to transposable elements falls into this category. There are ribosomal RNA and tRNA pseudogenes but the term usually refers to sequences that resemble protein-encoding genes.
February 8, 2008
Junk in Your Genome: Protein-Encoding Genes
The typical human gene has eight exons and seven introns (the actual average number of introns is 7.2). These values are based on analysis of 5236 well-characterized human genes with full-length cDNA's (Hong et al. 2006). There are lots of conflicting results in the literature. Most claim there are more introns but the data is based largely on a computational assessment of introns and exons. It includes a number of introns of extraordinary length lying between exons of dubious existence (often non-coding). I'll assume for the time being that there are 7.2 introns per gene, on average, and the average length is 3750 bp (Hong et al. 2006)
 February 9, 2008
February 9, 2008Junk in Your Genome: Intron Size and Distribution
There have been quite a few studies of average intron size in various species. I selected a number for the average size of introns from Hong et al. (2006). The average intron size, according to them, is 3,479 bp in coding regions. This value is a little deceptive since there are a small number of huge introns that make the average quite large. The median value is 1334 bp or less than half the average value.
February 20, 2008
An IDiot Software Developer Opines About Junk DNA
Randy "I want to believe" Stimpson is a software developer who thinks he understands biology. He has written a post where he claims Most DNA is not Junk. Doppelganger has already pointed out the most obvious faults with Randy's point of view [Software developer PROVES that there is no junkDNA*... and other stuff].I just want to comment on one small paragraph in order to clear up any confusion.
 May 23, 2008
May 23, 2008Fugu, Pharyngula, and Junk
PZ Myers writes about Random Acts of Evolution in the latest issue of Seed magazine. The subtitle says it all.
May 26, 2008
Centromere DNA
Human centromeres range from 0.3Mb to 5Mb in size (Cleveland et al. 2003). If the average centromeric region is 3Mb (3,000 kb) in size then 23 centromeres represents 2% of the entire genome sequence. Not all of this DNA is essential because, among other reasons, there is considerable variation between individuals in the length of a given centromere. Nevertheless, lets assume for the sake of our junk DNA calculation that all of it is essential.
 May 29, 2008
May 29, 2008Telomeres
Telomeres are sequences at the ends of linear chromosomes that protect the essential part of the chromosome from damage following repeated rounds of DNA replication.
June 3, 2008
Minimum Centromere Size in Plants
Thus, in a certain sense, some of the "excess" centromeric DNA is required as a buffer against the possibility of future deletions. The extra DNA does not contribute to the viability of the individual carrying it but it does contribute to the survival of that individual's offspring. At some point, the potential advantage in terms of offspring survival will become too small to have any influence on the lineage of an individual. This will define the maximum amount of "excess" DNA at the centromere.
 August 26, 2008
August 26, 2008The Trichoplax Genome
Trichoplax adherens is a very simple animal that moves about on surfaces like a gigantic amoeba and ingests any food that it flows over. There are thought to be several species of Trichoplax in addition to Trichoplax adherens. The sequence of its genome tells us something about the origins of animals.
August 28, 2008
Useful RNAs?
Some people think that much of the junk DNA in a genome can be explained away as genes for regulatory RNA. This is nonsense.
 August 30, 2008
August 30, 2008Genomics and Darwinism!?
The scientific research journal Genome Research is proposing to publish a special issue on "Genomics and Darwinism" to coincide with Darwin's 200th birthday.
September 18, 2008
Everything Is There for a Reason?
Nils Reinton of The Sciphu Weblog has just posted an article entitled Junk, DNA, RNA, Brain, Biology and Possible Solutions.
Nils makes the point that biology is very complex and we may only have scratched the surface.
September 16, 2008
How RNA Polymerase Binds to DNA

As is the case in bacteria, a substantial number of holoenzyme complexes will be bound non-specifically to DNA at any one time. The proportion is much, much higher in mammalian cells because of the presence of so much junk DNA in the genome. This has the effect of soaking up a lot of holoenzyme complexes.
Since the holenzyme complexes, like those in bacteria, are capable of initiating basal levels of transcription, we should not be surprised to find spurious transciption in all parts of the genome. These transcript will be rare but they will come from any site where RNA polymerase holoenzme can bind.
September 19, 2008
An Example of Faulty Logic from Cold Spring Harbor
A press release from Cold Spring Harbor Laboratory promotes the work of Michael Zhang and Adrian Krainer who work with splicing factors. In a typical attempt to hype the significance of the work, the press release claims that each human gene has many different variants produced by alternative splicing [CSHL team traces extensive networks regulating alternative RNA splicing].
That may or may not be correct—I happen to think it's mostly an artifact of EST cloning—but that's not the point I want to make here.
September 23, 2008
Discussing Junk DNA with an Adaptationist
Adaptationists are scientists who like to find adaptive explanations for all features of organism. For them the concept of junk DNA is difficult to swallow in spite of abundant scientific evidence and in spite of the fact that counter-explanations do not account for the data. Nils Reinton is a molecular biologist working in the field of medical diagnostics and he has been challenging the concept of junk DNA in the comment section of a recent posting. The title of that posting, Everything Is There for a Reason?, was direct response to an earlier posting from Nils where he claimed that we shouldn't label DNA as "junk" because it's a science stopper.
 September 15, 2008
September 15, 2008How Many Genes Do Nematodes Have? - Pristionchus pacificus Genome
A new nematode genome sequence was published this week. The species is Pristionchus pacificus, a parasite of the oriental beetle Examala orientalis (Dieteridh et al. 2008). The authors note that there is a different species of parasitic nematode associated with almost every species of beetle, which means that there are at least as many nematodes as insects.
The Pristionchus pacificus genome is 169 Mb in size, which is considerably larger than the size of the Caenorhabditis elegans genome (100 Mb). P. pacificus has 23,500 genes.
September 28, 2008
Discussing Junk DNA with an Adaptationist, Again
During the discussion in the comment to my posting, I challenged Nils to answer a number of questions. He has responded on his blog SciPhu with Hey junk people, I accept your challenge (part I). I resonded to his answers in Discussing Junk DNA with an Adaptationist.
Now Nils has weighed in with Hey junk people, I accept your challenge (part II).
October 28, 2008
Junk DNA Opponents Are at It Again
You are more than welcome to visit Sciphu and make comments. I can't be bothered.
The articles are just the same-old, same-old, litany of occasional discoveries of functional bits of DNA coupled with a fanatical belief in the biological significance of every single transcript that has ever been reported in the literature.
 November 7, 2008
November 7, 2008Is Andras Pellionisz a Kook?
Some of you may have heard of Andras Pellionisz. He has three Ph.D.s (Computer Engineering, Biology, Physics) and he maintains that much of what we know in biology is wrong. This is especially true of genomes. Whenever you mention junk DNA on a blog, Pellionisz will show up. Same when you mention the Central Dogma of Molecular Biology. He has a blog site that used to be called Junk DNA but it has morphed into HoloGenomics
January 27, 2009
Science Journalists and Junk DNA
The latest issue of SEED magazine concentrates on the idea that "Science Is Culture"—whatever that means.
One of the things it seems to mean is that good, accurate science reporting is not a high priority.
Junk DNA is one of those subjects that seem to bamboozle science journalists. They just can't seem to accept the possibility that much of our genome serves no purpose. One of the most extreme examples of this bias can be found in an article by Veronique Greenwood titled What We Lose.
 February 9, 2009
February 9, 2009Evolution of Pine Genomes
It's possible that different species of pine could have larger or smaller gene families. This would mean that the species with larger genomes have many more copies of some genes than species with smaller genomes. However, this is unlikely to account for much of the difference since simultaneous duplication events in all parts of the genome.
The most logical explanation is an increase in the amount of junk DNA, specifically the number of retrotransposons. Flowering plants have retrotrapsposons with long terminal repeats (LTRs) just like those found in animal genomes [Junk in your Genome: LINEs].
February 17, 2009
Junk DNA Is "Dead as a doornail"?
There are some interesting scientific debates about the role of noncoding DNA in large genomes. Much of it is junk but there's lot of other functions that we've known about for decades. Many respectable scientists dispute the notion that most of our genome is junk.
Unfortunately, very little of that interesting scientific debate can be seen on András Pellionisz's website. Instead, I direct you to the site in order to see a classic example of a modern kook in action. The site has all of the characteristics of kookdom (see crank) and serves as a self-evident answer to the question Is András Pellionisz a Kook?.
Tuesday, May 24, 2011
Junk & Jonathan: Part 6—Chapter 3
The title of Chapter 3 is Most DNA Is Transcribed into RNA. As you might have anticipated, the focus of Wells' discussion is the ENCODE pilot project that detected abundant transcription in the 1% of the genome that they analyzed (ENCODE Project Consortium, 2007). Their results suggest that most of the genome is transcribed. Other studies support this idea and show that transcripts often overlap and many of them come from the opposite strand in a gene giving rise to antisense RNAs.
Wednesday, May 25, 2011
Junk & Jonathan: Part 7—Chapter 4
Nothing new here. We know about binding sites and we know that most of them are 10 bp or less. Their presence makes no significant difference in our calculations of junk DNA. I get the distinct impression that Wells and the other IDiots don't really understand splicing and alternative splicing.
March 16, 2009
Casey Luskin on Junk DNA and Junk RNA
Intelligent Design Creationists can't abide junk DNA. Its very existence refutes the idea that living things are designed by some intelligent being. This is why the IDiots go out of their way to make up stories "disproving" junk DNA.
The latest attempt is by Casey Luskin [Nature Paper Shows "Junk-RNA" Going the Same Direction as "Junk-DNA"]. Having failed to explain why half of the human genome is composed of defective transposons, he now pins his hope on the idea that most of the genome is transcribed. Luskin seems particularly upset by my statement that most of these transcripts are junk [Junk RNA].
April 2, 2009Dynamic Genomes
There may have been a time in the past when scientists imagined a static genome that only changed slowly over millions of years. However, beginning in the 1960's we began to see the genome as a much more dynamic entity. The first evidence of this kind of genome came with the discovery of huge amounts of variation between individuals in a species.
This was followed by the discovery of transposons and junk DNA. We began to see genomes as rather sloppy DNA molecules with lots of pieces hopping in and out on a timescales of generations. We began to realize that many genomes were full of pseudogenes.
April 21, 2009
How to Evaluate Genome Level Transcription Papers
Here's two criteria that I use to evaluate a paper on genome level transcription.
1. I look to see whether the authors are aware of the adaptation vs noise controversy. If they completely ignore the possibility that what they are looking at could be transcriptional noise, then I tend to dismiss the paper. It is not good science to ignore alternative hypotheses. Furthermore, such papers will hardly ever have controls or experiments that attempt to falsify the adaptationist interpretation. That's because they are unaware of the fact that a controversy exists.1
2. Does the paper have details about the abundance of individual transcripts? If the paper is making the case for functional significance then one of the important bits of evidence is reporting on the abundance of the rare transcripts. If the authors omit this bit of information, or skim over it quickly, then you should be suspicious. Many of these rare transcripts are present in less that one or two copies per cell and that's perfectly consistent with transcriptional noise—even if it's only one cell type that's expressing the RNA. There aren't many functional roles for an RNA whose concentration is in the nanomole range. Critical thinkers will have thought about the problem and be prepared to address it head-on.
 May 6, 2009
May 6, 2009How to Frame a Null Hypothesis
The point is not whether you believe that all transcription is adaptive and functional, or whether you believe that most of it is noise. The real point is that it is very bad science to ignore the null hypothesis and publish naive speculation as if it were the only possible explanation.
Whenever you see a paper that fails to address the null hypothesis you can be sure that you are reading bad science. Everything else in the paper is suspect.
May 29, 2009
The Mouse Genome is "Finished"

The total length of protein-encoding exons in the mouse genome is 33,500 Kb (33.5 Mb). The revised genome size is 2,660,000 Kb (2.66 Gb). Thus, protein-encoding regions represent only 1.3% of the genome. This is similar to the value in the human genome (1.1% or 32.6 Mb out of 3.08 Gb).
There are many important non-coding sequences including centromeres, telomeres, origins of replication, scaffold attachment regions etc. All genes have substantial regulatory regions that aren't counted in the 1.3% of the genome that encodes protein. In addition, there are hundreds of tRNA genes, ribosomal RNA genes, and genes for essential small RNAs.
Nevertheless, a substantial proportion of the mouse genome (>90%) appears to be junk DNA with no known function. Most of it (~50%) consist of active and degenerate transposons similar to the LINES and SINES found in all other mammalian genomes.
July 8, 2009
Junk DNA and the Scientific Literature
The skill in reading the scientific literature is to put things into perspective and maintain a certain degree of skepticism. It's just not true that everything published in scientific journals is correct. An important part of science is challenging the consensus and many scientists try to make their reputation by coming up with interpretations that break new ground. The success of science depends on the few that are correct but let's not forget that most of them turn out to be wrong.
The trick is to recognize the new ideas that may be on to something and ignore those that aren't. This isn't easy but experienced scientists have a pretty good track record. Inexperienced scientists may not be able to distinguish between legitimate challenges to dogma and ones that are frivolous. The problem is even more severe for non-scientists and journalists. They are much more likely to be sucked in by the claims in the latest paper—especially if it's published in a high profile journal.
September 21, 2009
More Junk DNA Fallacies
BiOpinionated is a blog written by a molecular biologist named Nils Reinton. He tries to see every side of an argument but there are times when this attempt goes astray.
November 17, 2009
Genetic Load, Neutral Theory, and Junk DNA
A species cannot afford to accumulate deleterious mutations in the genomes of its individuals. Eventually the number of "bad" mutations will reach a level where most genes have multiple "bad" alleles and it becomes impossible to produce offspring.
This phenomenon is referred to as genetic load. It means that species can only survive if the genetic load is below some minimum value. A good rule of thumb is that there can't be more than 0.1 deleterious mutations per individual per generation but in actual populations this value can be a bit higher.
December 15, 2009
Does Excess Genomic DNA Protect Against Mutation?

One of the adaptive explanations for this excess DNA is that it protects the functional DNA from mutations. Ryan Gregory thinks this is a serious scientific hypothesis even though he's skeptical. He has a wonderful post that reviews the history of the idea and how the hypothesis should be tested [Does junk DNA protect against mutation?].
The bottom line is that this hypothesis is not taken very seriously by the scientific community for some very good reasons.
May 4, 2010
Shoddy But Not "Junk"?
The purpose of this posting is not to review the points that John Avise makes but to comment on one of the points made by Philip Ball. At the end of his Nature review he says,
However — although heaven forbid that this should seem to let ID off the hook — it is worth pointing out that some of the genomic inefficiencies Avise lists are still imperfectly understood. We should be cautious about writing them off as 'flaws', lest we make the same mistake evident in the labelling as 'junk DNA' genomic material that seems increasingly to play a biological role. There seems little prospect that the genome will ever emerge as a paragon of good engineering, but we shouldn't too quickly derogate that which we do not yet understand.
May 20, 2010
Junk RNA or Imaginary RNA?
RNA is very popular these days. It seems as though new varieties of RNA are being discovered just about every month. There have been breathless reports claiming that almost all of our genome is transcribed and most of the this RNA has to be functional even though we don't yet know what the function is. The fervor with which some people advocate a paradigm shift in thinking about RNA approaches that of a cult follower [see Greg Laden Gets Suckered by John Mattick].
May 23, 2010
Junk DNA on BIOpinionated
Nils Reinton and I are discussing junk DNA on his blog [More crap from the junkies]. It might surprise you to learn that this "junkie" still isn't convinced that junk DNA is dead. Nils isn't convinced that junk DNA exists.
This is what a real scientific controversy looks like.
May 28, 2010
Junk DNA and Genetics Textbooks
One of the things textbook authors have to careful of is discarding solid, well-established, models (like junk DNA) based on the results of a few modern experiments. Yes, it's true that new discoveries often overthrow old concepts, but it also true that when new "facts" disagree with established models it's usually the new facts that turn out to be wrong. The idea that theories are frequently overthrown by "nasty little facts" is a myth.
August 25, 2010
Bated Breath
Jonathan Wells made an annoucement that sets my heart all aflutter. I just can't wait for his new book to appear Zombie Genes?.
Richard Dawkins, Douglas Futuyma, Michael Shermer, Philip Kitcher, Kenneth Miller, Jerry Coyne and John Avise have also written recent books in which they argue that much of the human genome consists of "junk DNA" that provides evidence for Darwinian evolution--and evidence against intelligent design.
But the notion of "junk DNA" owes more to the historical contortions of neo-Darwinian theory than to biological evidence. In fact, there is now a large and growing body of evidence that Collins, Dawkins, Futuyma, Shermer, Kitcher, Miller, Coyne and Avise are dead wrong on this point--as I will show in my forthcoming book, The Myth of Junk DNA.
November 12, 2010
Darwinism and Junk DNA
I don't want to defend Francis Collins. I want to emphasize something else; namely that the concept of junk DNA is about as far removed from "Darwinism" as you can possibly be and still be an evolutionary biologist. If it has any meaning at all, "Darwinism" has to be a synonym for the belief in natural selection as the most potent mechanism of evolution. Junk DNA is completely non-Darwinian and there's no way you could describe it as compatible with "Darwinian theory."
February 27, 2011
Debating the Existence of Junk DNA
The sixth question for my students is ...
Do you think that most of the DNA in our genome is junk? Explain your answer.
May 8, 2011
What's in Your Genome?
This posting is a summary of the known components of the humna genome and how much of it is junk.
Total Essential/Functional (so far) = 8.7%
Total Junk (so far) = 65%
Unknown (probably mostly junk) = 26.3%
Tuesday, March 31, 2011
Junk & Jonathan: Part 1—Getting the History Correct
This is the first in a series of postings about a new book by Jonathan Wells: The Myth of Junk DNA. The book is published by Discovery Institute Press and it should go on sale on May 31 2011. I'm responding to an interview with Jonathan Wells on Uncommon Descent.
Friday, April 1, 2011
Junk & Jonathan: Part 2— What Did Biologists Really Say About Junk DNA?
It's in the best interests of the IDiots to promote the idea that all "Darwinists" believed in the "myth" of junk DNA and that it wasn't until the predictions of the IDiots were confirmed (not) that the biologists changed their minds.
The truth is somewhat different. Wells says, "Some people revise history by claiming that no mainstream biologists ever regarded non-protein-coding DNA as “junk.”" The truth is that the mainstream biologist community never, ever claimed that all non-coding DNA was junk. Most of them didn't even believe that a majority of our genome was junk.
Thursday, April 7, 2011
Jonathan, Moonies, and Junk DNA
This video is supposed to support the evolution side versus the Intelligent Design Creationists. There are two major flaws in this presentation.
First, it spends too much time on the background of Jonathan Wells. While it's interesting to know where he's coming from, his motives are less important that the "scientific" case he's making. His religious motivation explains WHY he gets the science wrong but the important point is that the science IS wrong.
 May 3, 2011
May 3, 2011Junk & Jonathan: Part 3—The Preface
Here's the preface to The Myth of Junk DNA by the IDiot, Jonathan Wells. After each paragraph I've inserted a short version of the truth just so you don't get misled by all the untruths and distortions that are found in creationist books.
Monday, May 16, 2011
See the IDiots Gloat over Jonathan Wells
This the start of the discussion now that Wells' book has been published. It doesn't start well ...
The IDiots have a bit of a problem. In order to make this book look important they have to first establish that the concept of abundant junk DNA in our genome was a "pillar" of support for evolution. That's hard to do when their understanding of evolution is so flawed that they don't see the difference between "Darwinism" and evolution by random genetic drift.
Sunday, May 22, 2011
Junk & Jonathan: Part 4—Chapter 1
I received a copy of the book a few days ago and this is my first posting on its contents....
Chapter 1 is "The Controversy over Darwinian Evolution." It has nothing to do with junk DNA.
Monday, May 23, 2011
Junk & Jonathan: Part 5—Chapter 2
Wells fails to distinguish between those biologists who recognize the existence of junk DNA (e.g. pseudogenes) and those who thought that most of our genome is junk. I still believe that only a minority of biologists think that most our genome is junk. I also think that many biologists make a distinction between "junk" and "selfish." I know I do. In my mind "selfish" DNA, such as active transposons or endogenous retroviruses, isn't junk.
Tuesday, May 24, 2011
Junk & Jonathan: Part 6—Chapter 3
The title of Chapter 3 is Most DNA Is Transcribed into RNA. As you might have anticipated, the focus of Wells' discussion is the ENCODE pilot project that detected abundant transcription in the 1% of the genome that they analyzed (ENCODE Project Consortium, 2007). Their results suggest that most of the genome is transcribed. Other studies support this idea and show that transcripts often overlap and many of them come from the opposite strand in a gene giving rise to antisense RNAs.
Wednesday, May 25, 2011
Junk & Jonathan: Part 7—Chapter 4
Nothing new here. We know about binding sites and we know that most of them are 10 bp or less. Their presence makes no significant difference in our calculations of junk DNA. I get the distinct impression that Wells and the other IDiots don't really understand splicing and alternative splicing.

Thursday, May 26, 2011
Junk & Jonathan: Part 8—Chapter 5
Chapter 5 is Pseudogenes—Not so Pseudo After All. This is the chapter where Jonathan Wells takes the standard creationist approach to the problem of pseudogenes—he denies that they exist!
 Tuesday, August 11, 2011
Tuesday, August 11, 2011Junk & Jonathan: Part 9—Chapter 6
The title of Chapter 6 is "Jumping Genes and Repetitive DNA." Wells describes transposons as jumping genes and includes them in the category of "Repetitive Non-Protein-Coding DNA." This category makes up 50% of the genome, according to Wells. The breakdown is as follows. LINES 21%; SINES 13%; retroviral-like elements 8%; simple sequence repeats 5%; and DNA-only transposons 3%. These percentages are similar to those published in a wide variety of textbooks and scientific papers.
 Monday, August 23, 2011
Monday, August 23, 2011Junk & Jonathan: Part 10—Chapter 7
The title of Chapter 7 is "Functions Independent of Exact Sequence." This is potentially the most important chapter in the book because it should address some of the serious arguments for function in the genome. We already know that sequence is not conserved in the vast majority of the genome that we call junk so in order for it to have a function it must be due to the presence of built DNA.Thursday, August 25, 2011
Junk & Jonathan: Part 11—Chapter 8
The title of Chapter 8 is "Some Recent Defenders of Junk DNA." It is Wells' attempt to deal with a very small percentage of the criticisms of his claim.
Tuesday, October 11, 2011Junk & Jonathan: Part 12—Chapter 9
The title of Chapter 9 is "Summary of the Case for Functionality in Junk DNA." It is Wells' attempt to summarize the "evidence" he has presented so far.
Wells tells us that the "evidence" falls into two broad categories: (1) evidence that putative junk is probably functional, and (2) evidence that small specific bits of the genome are functional.
Friday, January 25, 2013
How Many Genomes Have Been Sequenced?
How many "finished" or permanent draft complete genome sequences have been published?
How many of them are eukaryotes?

What Is a Mutation?
I've said it before and I'll say it again, biology is messy. It's really hard to rigorously define simple terms because there are always exceptions. Just think of the problems we've had trying to define a gene [What Is a Gene?].
"Mutation"¹ is almost as difficult. First, we want to distinguish between a mutation and DNA damage.
Wednesday, March 13, 2013
Ford Doolittle's Critique of ENCODE
Ford Doolittle has never been one to shy away from controversy so it's not surprising that he weighs in against the misleading publicity campaign launched by ENCODE leaders last September (Doolittle, 2013). Recall that Ewan Birney and other prominent members of the consortium promoted the idea that our genome contained an extensive array of regulatory elements and that 80% of our genome was functional [Ewan Birney: Genomics' Big Talker] [ENCODE Leader Says that 80% of Our Genome Is Functional] [The ENCODE Data Dump and the Responsibility of Scientists].
Thursday, March 14, 2013
Anonymous Nature Editors Respond to ENCODE Criticism
A few days ago (March 12, 2013) the editors of Nature published another response to criticism [Form and Function]. These editors don't identify themselves.
Let's see how they do by analyzing each part of the editorial. Let's begin with the subtitle ...

On the Meaning of the Word "Function"
A lot of the debate over ENCODE's publicity campaign concerns the meaning of the word "function." In the summary article published in Nature last September the authors said, "These data enabled us to assign biochemical functions for 80% of the genome ...." (The ENCODE Project Consortium, 2012).
Here's how they describe function.

Estimating the Human Mutation Rate: Biochemical Method
This is the second in a series of posts on human mutation rates and their implication(s). The first one was ...
What Is a Mutation?
There are basically three ways to estimate the mutation rate in the human lineage. I refer to them as the Biochemical Method, the Phylogenetic Method, and the Direct Method.
The biochemical method relies on the well-known fact that the vast majority of mutations are due to errors in DNA replication. Since we know a great deal about the replication complex and the biochemistry of the reactions, we can calculate a mutation rate per DNA replication based on this knowledge. The details are explained in a previous post [Mutation Rates]. I'll give a brief summary here.
Monday, March 18, 2013
ENCODE & Junk and Why We Call Them IDiots
The Intelligent Design Creationists have been following the debate over the ENCODE results. For them this is a serious issue since they are committed to the idea that well-designed genomes should not be full of junk. You'd think that the IDiots would make an attempt to learn the real scientific issues at stake.

Estimating the Human Mutation Rate: Phylogenetic Method
The phylogenetic method relies on a known phylogenetic tree to pick out close relatives and the approximate time to the last common ancestor. In the case of humans, we know that chimpanzees and bonobos are our closest cousins and we think that the homind line diverged from the chimp line about 5 million years ago.
If we count mutations in chimps and humans we can assume that these mutations have been accumulating since the time of the last common ancestor. This can be converted to a mutation rate if we know that the mutations are neutral. That's because, according to population genetics, the rate of fixation of neutral alleles by random genetic drift is equal to the mutation rate.

Estimating the Human Mutation Rate: Direct Method
The Direct Method involves sequencing the entire genomes of related individuals (e.g. mother, father, child) and simply counting the new mutations in the offspring. You might think that the Direct Method gives a definitive result that doesn't rely on any assumptions, therefore it should yield the most accurate result. The other two methods should be irrelevant.
This would be true if the Direct Method were as easy as it sounds but things are more complicated.

ENCODE, Junk DNA, and Intelligent Design Creationism
It's true that there are some IDiots who are distancing themselves from a commitment to junk DNA. There are probably some who claim that they could live with the fact that 90% of our DNA is junk.
But let's not forget that Jonathan Wells is a prominent IDiot and he wrote a book on The Myth of Junk DNA. It sounded very much like Intelligent Design Creationism is staking its reputation on finding function for most of our genome.
Have you heard of someone named Stephen Meyer? He wrote a book called Signature in the Cell and that book seems to be widely admired in the IDiot community. I think it's been mentioned once or twice on the Intelligent Design Creationist blogs. I blogged about what Meyer wrote about junk DNA a few years ago [Stephen Meyer Talks About Junk DNA]. Here's part of what's in that post, quoting from Stephen Meyer's book ....
Wednesday, April 3, 2013
Understanding the ENCODE Results
Josh Witten of The Finch and the Pea participated in a video discussion about the ENCODE results [see Decoding ENCODE]. The hosts are Rajini Rao, Buddhini Samarasinghe and Scott Lewis. The other guest is Ian Bosdet. The goal is to explain the controversy over ENCODE in a way that the general public can understand.
Post a comment and let me know what you think. Do you understand the issues after watching the video?
Thursday, April 4, 2013
Hank Green Talks About Junk DNA
A reader gave me a link to a video that was posted on Genetic Engineering & Biotechnology News (GEN) just a few days ago (March 25, 2013). The video was made by Hank Green of SciShow. Hank has a bachelor's degree in biochemistry and a master's degree in environmental studies.
The video is interesting for two reasons: (1) it shows how a typical scientifically literate person interpreted the ENCODE publications, and (2) it show how a business publication treats the results almost seven months later. Here's how GEN introduces the video ...
Tuesday, April 9, 2013
Educating an Intelligent Design Creationist: Pervasive Transcription
The idea that most of the human genome is transcribed dates back to the early 1970s. Workers isolated RNA from various sources and hybridized it to DNA (Rot analysis). They measured the amount of DNA that was complementary to this RNA and discovered two things:
Using highly purified messenger RNA (mRNA) the amount of DNA suggested that the genome had between 15,000 and 20,000 genes.
Using heterogeneous nuclear RNA (hnRNA) a much larger percentage of the genome was covered. This included the repetitive DNA fraction that we now know consist mostly of defective transposons.
Wednesday, April 10, 2013
Evolution and Junk DNA in Chicago
I just signed up for the SMBE Conference in Chicago in July. There's lots of cool talks about evolution but, in the end, I decided I just couldn't miss the session on "Where did 'junk' go?" with Wojciech Makalowski as organizer.
Thursday, April 11, 2013
Educating an Intelligent Design Creationist: Rare Transcripts
I'm replying to a post by andyjones (More and more) Function, the evolution-free gospel of ENCODE. This was the fourth post in a series and I'm working my way through five issues that Intelligent Design Creationists need to understand.
Thursday, April 11, 2013
Educating an Intelligent Design Creationist: The Specificity of DNA Binding Proteins
I'm replying to a post by andyjones (More and more) Function, the evolution-free gospel of ENCODE. This was the fourth post in a series and I'm working my way through five issues that Intelligent Design Creationists need to understand. The first two were "Pervasive Transcription" and "Rare Transcripts."
Friday, April 12, 2013
Educating an Intelligent Design Creationist: The Meaning of Darwinism
Intelligent Design Creationists love to refer to their opponents as "Darwinists." We all know why they do it. It's a rhetorical device designed to belittle those who accept evolution. The term makes it look like evolutionary biologists worship a man who died 130 years ago and it implies that we still believe in nineteenth century science. The term "Darwinist" also makes it easy to associate modern scientists with social Darwinism. That's a common strategy employed by creationists of all stripes. I get it. It has nothing to do with scientific debates about evolution.
Tuesday, April 16, 203
Educating an Intelligent Design Creationist: Evidence for Junk
Intelligent Design Creationists have difficulty understanding the arguments for junk DNA and the evidence that supports those arguments. We try to explain the genetic load argument but it doesn't seem to penetrate. We try to explain that half of our genome is composed of defective transposons and viruses—often fragments of the intact genes. This doesn't phase them. And no matter how many times we describe the "C-value Paradox" and why junk DNA resolves the paradox, that evidence is ignored. We patiently describe the megabase pair deletions of the mouse genome and why this is evidence of junk. We teach them about copy number variation in the human genome and why DNA fingerprinting works. We show them examples of deletions and insertions in the genomes of different individuals telling them that these seem to have no effect as far as we know. We take time to explain modern evolutionary theory and why it is consistent with junk DNA. Finally, we describe our detailed textbook understanding of transcription and DNA binding proteins and they don't listen.
Thursday, May 9, 2013
On My Failure to Educate an Intelligent Design Creationist
A few weeks ago I decided to give Intelligent Design Creationist andyjones the benefit of the doubt and assumed that he really wanted to understand enough biology to have a credible opinion about genomes and junk DNA. I published a series of posts on Educating an Intelligent Design Creationist: Introduction.
Friday, May 10, 2013
Andyjones Replies
This is all very frustrating. Why do IDiots who have no serious training in biochemistry and molecular biology think they know more than the experts?
And why do they refuse to learn when we attempt to educate them?

What Does the Bladderwort Genome Tell Us about Junk DNA?
Jonathan Eisen doesn't think much of the evidence from genome size comparisons. He thinks that other plants might need that extra DNA. It could have a function in those plants but those functions are not needed in the bladderwort. He suggests that it could be like the loss of legs in snakes. Just because snakes don't have legs doesn't mean that legs have no function in other species [Twisted tree of life award #15: NBC News on "Junk DNA mystery"]. It's a silly argument but Jonathan Eisen thought that it was important enough to give a "Twisted Tree of Life Award" to press reports that touted the small bladderwort genome as evidence for junk DNA.
Ryan Gregory set him straight by explaining why these genome size comparisons really do provide evidence that most of the genome is junk [Genome reduction in bladderworts vs. leg loss in snakes].

Laurence Hurst Discusses Junk DNA
Laurence Hurst is a Professor of Evolutionary Genetics in the Department of Biology and Biochemistry at The University of Bath (United Kingdom). He did his graduate studies under W.D. Hamilton at Oxford so it's safe to assume that he has adaptationist leanings.
Hurst wrote a comment in BMC Biology where he criticized the logic employed by those of us involved in the junk DNA debate [Open questions: A logic (or lack thereof) of genome organization]. Here's part of what Hurst says about logic ...

John Mattick on the Importance of Non-coding RNA
Mattick is interested in the evolution of complexity. For example, he wants to know why humans are much more complex than nematodes. Mattick was one of those scientists who expected that the human genome would contain many more genes than the nematode genome in spite of all evidence to the contrary [see Facts and Myths Concerning the Historical Estimates of the Number of Genes in the Human Genome]. When the human genome sequence was published he was shocked to learn that humans had the same number of genes as most other multicellular organisms. I refer to this as: The Deflated Ego Problem.
Tuesday, July 2, 2013
Keep Calm and Ask About Onions
Nick Matzke is going to the SMBE (Society for Molecular Biology and Evolution) meeting in Chicago next week. He's created a T-shirt for supporters of junk DNA [KEEP CALM and ASK ABOUT ONIONS].

Tuesday, July 2, 2013
Will There Be a Junk DNA Debate in Chicago?
Quite a few people think that there's going to be a serious debate about junk DNA at the SMBE meeting in Chicago next week. One of the sessions has a provocative title, "WHERE DID 'JUNK' GO?", but if you look at actual session titles it doesn't look like there's going to be much of a debate.
Tuesday, July 2, 2013
A Philosopher Trashes Junk DNA
I am one of those scientists who think that the discipline of "philosophy of science" is catering to some pretty stupid philosophers. Dan Graur found one of them, his name is Max Andrews and he's a graduate student in philosophy at the University of Edinburgh, Scotland ["I’ve Got a Little List" & “Let the Punishment Fit the Crime"].
Thursday, July 4, 2013
How to Make a Scientific Argument
The problem with the debate is that the scientific literature is full of papers attacking junk DNA while there are very few papers promoting it. This is partly because there haven't been any new discoveries in favor of junk DNA. On the other hand, there have been quite a few discoveries showing that some small part of the genome that was thought to be junk might have a function. Even though these discoveries make an insignificant contribution to the big picture, they are often blown up out of all proportion and promoted as an end to junk DNA.
Thursday, July 4, 2013
Five Things You Should Know if You Want to Participate in the Junk DNA Debate
Here are five things you should know if you want to engage in a legitimate scientific discussion about the amount of junk DNA in a genome.

What Did Dan Graur Say in Chicago?
Dan Graur gave a fantastic and entertaining talk at SMBE2013 [Powerpoint]. He covered a lot of bases, but unfortunately left some out 'cause he had many slides that he didn't get to because of time limitations. Most of the audience enjoyed the talk very much—there was much laughter and enthusiastic head nodding. (I figure that two thirds of the audience agreed with his stance on junk DNA and ENCODE.)

Every non-lethal genome position is variable in the human population
Melissa Wilson Sayres blogs at mathbionerd and Panda's Thumb. A recent post on Panda's Thumb address a tweet from Daniel Wegmann where he said "Every non-lethal genome position is variable in the human population."
She asks "Is this true?" and proceeds to show that it is [How many mutations?]. She assumes that the human mutation rate is 1.2 × 10-8 per sit per generation. Multiply this by 7.16 billion people on the planet and you get an average of 86 mutations at every single base pair in the human genome.
Wednesday, July 31, 2013
The Dark Matter Rises
John Mattick publishes lots of papers. Most of them are directed toward proving that almost all of the human genome is functional. I want to remind you of some of the things that John Mattick has said in the past so you'll be prepared to appreciate my next post [The Junk DNA Controversy: John Mattick Defends Design].
Thursday, August 1, 2013
The Junk DNA Controversy: John Mattick Defends Design
John Mattick has just published a paper dealing with the controversy over the ENCODE results and junk DNA. As you might imagine, Mattick defends the idea that most of our genome is functional. He attempts to explain why most of the critics are wrong.
The title of the paper is "The extent of functionality in the human genome" (Mattick and Dinger, 2013). It's published in the HUGO Journal. Recall that HUGO (Human Genome Organization) gave Mattick a prestigious award for his contributions to genome research. (See The Dark Matter Rises for a discussion of these contributions.)

Welcome Trust Sanger Institute Misleads Public About Junk DNA
Khurana er al. (2013) have just published a nice paper in Science where they analyzed 1009 human genomes in order to detect variants that might be linked to certain diseases (especially cancer). They focused on noncoding regions since it is much harder to recognize mutations in regulatory regions and these are leading candidates for cancer-causing mutations. What they did was identify conserved sequences and look for variants withing those presumptive regulatory sequences.
There's nothing in the paper about junk DNA and nothing about the overall organization of the human genome. Indeed, the tone of the paper is exactly what you would expect from a group of scientists who know that parts of noncoding DNA are involved in gene regulation.
But here's what the press release from the Welcome Trust Sanger Institute says [New technique identifies novel class of cancer's drivers].

Non-Darwinian Evolution in 1969: The Case for Junk DNA
Let's look at a famous paper by Jack Lester King and Thomas Hughes Jukes.1 The title of the paper is "Non-Darwinian Evolution" and it was published 44 years ago in the May 16, 1969 issue of Science [read it at: Science 164:788-798].
The subtitle of the paper is "Most evolutionary change in proteins may be due to neutral mutations and genetic drift" but that's not what I want to talk about. This paper is among the first to predict the presence of large amounts of junk DNA in our genome. King and Jukes didn't call it "junk"—that term was introduced by Susumu Ohno in 1972—but that doesn't matter. When King and Jukes talk about "superfluous DNA" they mean "junk."
Monday, October 21, 2013
Jukes to Crick on Junk DNA
Meanwhile, a person named "ShadiZl" commented on one my posts and pointed me to a letter from Thomas Jukes to Francis Crick in 1979. Jukes, you might recall, was no Darwinian. He was a proponent of Neutral Theory and random genetic drift. The letter is archived on the National Library of Medicine (USE) site under a section devoted to The Francis Crick Papers: Letter from Thomas H. Jukes to Francis Crick.
The letter is interesting because it reveals how casually the "insiders" talked about junk DNA and about the adaptationist misconception even as far back as 1979. This was when Gould and Lewontin published the "spandrels" paper.

Stop Using the Term "Noncoding DNA:" It Doesn't Mean What You Think It Means
Axel Visel is a member of the ENCODE Consortium. He is a Staff Scientist at the Lawrence Berkeley National Laboratory in Berkeley, California (USA). Axel Visel is responsible, in part, for the publicity fiasco of September 2012 where the entire ENCODE Consortium gave the impression that most of our genome is functional.
Thursday, November 21, 2013
Claudiu Bandea Shows Why Attacking Dan Graur Is a Very Bad Idea
It's not a good idea to attack someone who; (a) is an expert in the field, (b) is intelligent and outspoken, and (c) has a blog. But that never stopped Claudiu Bandea before so why should it now?
Here's part of how Dan Graur responds at: A Pre-Refuted Hypothesis on the Subject of “Junk DNA”. There's more, read it all.

1001 Ideas that Changed the Way We Think - "Not-junk DNA"
The last great idea that changed the way we think (#1001) is written by Simon Adams, a "historian and writer living and working in London." Simon Adams thinks that the discovery that most of our genome is not junk counts as a big idea. To his credit, Glenn Branch realizes that this is somewhat controversial.

On the function of lincRNAs
One way to decide if the genes for these RNAs are actually doing something is to disrupt them by knocking them out and looking for an effect. That's what Savageau et al. (2013) did with 18 genes for mouse link RNAs. They found that five of the mutant strains of mice had severe developmental defects that were often lethal (Fendrr, Peril, and Mdgt: mice with a deleted Mdgt lincRNA gene are shown in the photo). Two other strains, linc-Brn1b, and linc-Pint had less severe developmental defects.

Can some genomes evolve more slowly than others?
This brings me to a paper that's just been published in Nature. The authors sequenced a cartilaginous fish, the elephant shark (Callorhimchus milii). This is interesting because the cartilaginous fish (Chrondrichthyes) and the bony vertebrates (Osteichthyse) are thought to have diverged about 450 million years ago (Myr). This is the first complete genome of a cartilaginous fish.
The genome is only about 1/3 the size of the human genome and it has about 19.000 protein-coding genes and hundreds of other genes that specify various RNAs. The authors constructed phylogenetic trees using a set of 699 genes that had orthologues in 12 other chordates. They confirmed that the cartilaginous fish (sharks) diverged early from the bony vertebrates, as expected.
But the big news—see the cover of Nature—is that the genome of the elephant shark is the slowest evolving vertebrate genome.
Friday, February 28, 2014
Why are the human and chimpanzee/bonobo genomes so similar?
If evolutionary theory (population genetics) is correct, and if David Klinhoffer and chimps/bonobos actually evolved from a common ancestor, then we should observe a correspondence between the percent similarity of Klinghoffer and chimps and the predicted number of changes due to evolution.
Let's see if it works.
Monday, March 3, 2014
Death of the genome paper
David Smith of Western University (London, Ontario, Canada) laments the death of the genome paper while recognizing that sequencing has probably been abused (Smith, 2013). He makes some good points ...
Saturday, March 22, 2014
An Intelligent Design Creationist explains why chimpanzees and humans are so similar
It's been four weeks since I posted my original calculations and no creationist has responded until now. I mentioned this the other day when I was discussing Vincent Torley's strange views about macroevolution [What do Intelligent Design Creationists really think about macroevolution?].
I guess Torley is embarrassed by the fact that although some of his colleagues pretend to be scientists they didn't dare respond to my post. Torley is a philosopher but he isn't afraid to tackle science questions as we saw in his attempt to refute macroevolution.
Sunday, March 23, 2014
IDiots respond to the evidence for evolution of chimpanzees and humans
It's interesting to read the comments below Vincent Torley's post. You'd expect to see comments from the scientifically literate creationists pointing out that my calculations are basically correct and the IDiots better learn how to deal with it. After all, none of this is complicated stuff. It's the sort of evolution you would find in any introductory textbook.
Well, so far there haven't been any comments from IDiots who understand evolution.
One of the people who commented is Salvador Cordova (scordova) who teaches at George Mason University in Virginia (USA).
Sunday, April 6, 2014
The American Society of Plant Biologists embarrasses itself by publishing "New functions for 'junk' DNA?"
We now know that non-coding DNA can have important functions other than encoding proteins. Many non-coding sequences produce RNA molecules that regulate gene expression by turning them on and off. Others contain enhancer or inhibitory elements. Recent work by the international ENCODE (Encyclopedia of DNA Elements) Project (1, 2) suggested that a large percentage of non-coding DNA, which makes up an estimated 95% of the human genome, has a function in gene regulation. Thus, it is premature to say that "junk" DNA does not have a function—we just need to find out what it is!

The Case for Junk DNA: The onion test
I draw your attention to a new paper on junk DNA by my friends Alex Palazzo and Ryan Gregory (Palazzo and Gregory, 2014).
You should read this paper if you want a nice summary of the evidence for a high percentage of junk in our genome. They cover genetic load, sequence conservation, and the evidence from the genome sequence itself. There's a brief description of the nearly-neutral theory of molecular evolution and why it's relevant to the debate.
Friday, May 9, 2014
How does Nature deal with the ENCODE publicity hype that it created?
If the ENCODE Consortium leaders really meant something different that what was being reported in the media then they should have spoken up loud and clear in September 2012. They should have disavowed all the quotations that were attributed to them and they should have made it very clear that their results did not mean the end of junk DNA.
But I don't believe for a second that the 80% claim was misunderstood and misreported. I believe that most Consortium leaders really believed that there was almost no junk in our genome. I think most of them still believe this.
But there's another issue. No matter how you look at it, Nature was wrong. Either they were wrong because most of our genome is junk (as I believe) or they were wrong because they misrepresented the ENCODE results (as Kellis claims).
I wonder when we can expect an apology and a retraction from Nature? Or Science?

What did the ENCODE Consortium say in 2012?
In most cases, those articles contained interviews with ENCODE leaders and direct quotes about the presence of large amounts of functional DNA in the human genome.
The second wave of the ENCODE publicity campaign is trying to claim that this was all a misunderstanding. According to this revisionist view of recent history, the actual ENCODE papers never said that most of our genome had to be functional and never implied that junk DNA was dead. It was the media that misinterpreted the papers. Don't blame the scientists.
Wednesday, June 25, 2014
The Function Wars: Part I
I believe that this strange way of redefining biological function was a deliberate attempt to discredit junk DNA. It was quite successful since much of the popular press interpreted the ENCODE results as refuting or disproving junk DNA. I believe that the leaders of the ENCODE Consortium knew what they were doing when they decided to hype their results by announcing that 80% of the human genome is functional.
Tuesday, July 1, 2014
The Function Wars: Part II
I addressed the meaning of "function" in Part I It is apparent that philosophers and scientists are a long way from agreeing on an acceptable definition. There has been a mini-explosion of papers on this topic in the past few years, stimulated by the ENCODE Consortium publicity campaign where the ENCODE leaders clearly picked a silly definition of "function" in order to attract attention.
Monday, July 28, 2014
How many genes do we have and what happened to the orphans?
The most recent estimates are 20,807 protein-encoding genes, 9,096 genes for short RNAs, and 13,870 genes for long RNAs. This gives 43,773 genes. Nobody knows for sure how many of the putative genes for RNAs actually exist. They may only be a few thousand functional genes in this category.
It's a lot easier to figure out whether a gene really encodes a functional protein so most of the annotation effort is focused on those genes. I want to draw your attention to a recent paper by Ezkurdia et al. (2014) that discusses this issue. The authors begin with a bit of history ...
Monday, July 28, 2014
How many genes do we have and what happened to the orphans?
The bottom line is that 1867 of the 20,719 protein-encoding genes are probably not genes. On the other hand, the authors found evidence for 58 new genes that are currently not annotated. The total number of protein-encoding genes is now estimated to be 18,910 or about 19,000.
Nobody knows how to apply this type of rigorous analysis to all those predicted genes that might make a functional RNA product. Based on our knowledge of the annotation process for protein-encoding genes, we might expect that a large percentage of those putative RNA genes will turn out to be false predictions.
You may think that this is a pretty esoteric exercise that has few consequences for researchers but that's not true. Falsely annotated genes can lead to false predictions about protein domains and gene families and these propagate in the databases. As the authors put it,

Tuesday, July 29, 2014
The Function Wars: Part III
The best way to define "function" is to rely on evolution. DNA that is under selection is functional. But how can you determine whether a given stretch of DNA is being preserved by natural selection? The easiest way is to look at sequence conservation. If the sequence has not changed at the rate expected of neutral changes fixed by random genetic drift then it is under negative selection. Unfortunately, sequence conservation only applies to regions of the genome where the sequence is important. It doesn't apply to DNA that is selected for its bulk properties.
Let's look at how much of the human genome is conserved (sequence). Keep in mind that this value has to be less than 10% based on genetic load arguments. It should be less than 5%.
Thursday, August 7, 2014
The Function Wars: Part IV
In the third post I discussed a paper by Rands et al. (2014) presenting evidence that about 8% of the human genome is conserved [The Function Wars: Part III]. This is important since many workers equate sequence conservation with function. It suggests that only 8% of our genome is functional and the rest is junk. The paper is confusing and I'm still not sure what they did in spite of the fact that the lead author (Chris Rands) helped us out in the comments. I don't know what level of sequence similarity they counted as "constrained." (Was it something like 35% identity over 100 bp?)
My position if is that there's no simple definition of function but sequence conservation is a good proxy. It's theoretically possible to have selection for functional bulk DNA that doesn't depend on sequence but, so far, there are no believable hypothesis that make the case. It is wrong to arbitrarily DEFINE function in terms of selection (for sequence) because that rules out all bulk DNA hypotheses by fiat and that's not a good way to do science.
So, if the Rands et al. results hold up, it looks like more that 90% of our genome is junk.
Let's see how a typical science writer deals with these issues. The article I'm selecting is from Nature. It was published online yesterday (Aug. 6, 2014) (Woolston, 2014). The author is Chris Woolston, a freelance writer with a biology background. Keep in mind that it was Nature that started the modern functions wars by falling hook-line-and-sinker for the ENCODE publicity hype. As far as I know, the senior editors have not admitted that they, and their reviewers, were duped.
Tuesday, December 9, 2014
How many microRNAs?
The journal Cell Death and Differentiation has devoted a special issue to microRNAs [Special Issue on microRNAs – the smallest RNA regulators of gene expression]. There are four reviews on the subject but none of them address the big questions.
That didn't stop the journal from leading off with this introduction ...

A lesson on genetic load
Dan Graur has written an excellent summary of the genetic load argument from the perspective of population genetics. He links to it from his blog: If @ENCODE_NIH is right, each of us should have 7 x 1045 children.
Tuesday, February 10, 2015
Nessa Carey and New Scientist don't understand the junk DNA debate
This is not looking good. Anyone who starts with the premise that noncoding DNA might all be junk is clearly way out of their depth in this debate. The claim that epigenetics might explain junk DNA is another dead giveaway. Looks like we're dealing with an amateur.
Fortunately, we don't have to wait for the book to make a decision. She has a website and one of the pages is on Junk DNA - The Basics.
Tuesday, February 24, 2015
How do you explain the differences between chimpanzees. humans, and macaques?
Notice that the substitutions are pretty much randomly scattered over every part of the two chromosomes. The data is consistent with the idea that most of the DNA in those chromosomes is junk and most of the substitutions are nearly neutral mutations fixed by random genetic drift. The differences between each pair of species is consistent with an approximate molecular clock corresponding to a constant mutation rate over million of years. The absolute levels of sequence identity (i.e. 98-99% for chimp/human) is consistent with the time of divergence from a common ancestor based on the fossil record and other criteria.


Is most of our DNA garbage?
Carl Zimmer's article on junk DNA has appeared in the online edition of the New York Times magazine at: Is Most of Our DNA Garbage?.
Carl was in Toronto and Guelph last December gathering information for his article. You can see that Ryan Gregory is featured and my colleague Alex Palazzo gets quoted.
Tuesday, March 10, 2015
A physicist tries to understand junk DNA
Rob Sheldon has a PhD. in physics and a M.A. in religion.1 With two strikes against him already, he attempts to understand biology by discussing evolution, junk DNA, and the Onion Test [Physicist suggests: “Onion test” for junk DNA is challenge to Darwinism, not ID]. As you might imagine, posting on Uncommon Descent in support of Intelligent Design Creationism leads directly to strike three.
Wednesday, March 11, 2015
A physicist tries to understand junk DNA: Part II
To say that the Onion Test has something to do with assuming that the only job of DNA is to make protein is either incredibly stupid or a blatant lie. Probably both. To claim that this has something to do with the Central Dogma of Molecular Biology is also a lie.
To say that once we discovered functions for noncoding DNA, back in the 1960s, the Onion Test made no sense, is in the same category. It's a lie and furthermore it's a lie that could only be believed by someone who is very stupid about this subject, like Rob Sheldon (see photo above).
Saturday, March 21, 2015
Junk DNA comments in the New York Times Magazine
The most common approach was from commenters who thought that junk DNA was just a term to describe our ignorance of what's in the genome. They believe that scientists know very little about genomes and that's why they came up with the junk DNA concept. Words like "hubris" and "arrogance" are thrown about.
This is a problem because it indicates a mistrust of scientists and a misunderstanding of how science works. But in fairness, there are a good number SCIENTISTS who also think that there's no evidence for junk DNA.

How the genome lost its junk according to John Parrington
The title of the promotion blurb is: How the Genome Lost its Junk on the Canadian version of the Oxford University Press website. It looks like this book is going to be an attack on junk DNA.
We won't know for sure until June or July when the book is published. Until then, the author and the publisher will have free reign to sell their ideas without serious opposition or push back.
Friday, March 27, 2015
Plant biologists are confused about the meanings of junk DNA and genes
A recent issue of Nature contains a report on plant micro-RNAs (Lauressergues et al., 2015). The authors found that certain genes for plant micro-RNAs encoded short peptides in the micro-RNA presursors and those peptides seemed to have a biological function. What this means is that part of the longer precursor RNA that is cleaved to produce the final micro-RNA may have a function that wasn't recognized. If you thought that the part of the precursor that was thought to be discarded as useless junk was, in fact, junk, then you were wrong—at least for some genes.
This is not a big deal and the authors of the paper don't even mention junk DNA.

Human mutation rates - what's the right number?
The implications for recent human evolution are complicated, but interesting. Mayer et al. sequenced a Denisovan genome and calculated that it differs from the genome of a modern human at 4.88 million sites. He assumed that humans and chimpanzess last shared a common ancestor 6.5 million years ago so this means that the Denisovan lineage separated from the modern human lineage about 800,000 years ago giving a mutation rate of 92 mutations per generation. If the actual rate is 130 mutations per generation, then the split occurred only 600,000 years ago.
This seems like a problem but there are all kinds of potential errors in these calculations. For one thing, we don't know how accurate the Denesovan sequence is and what the real number of differences are. There are also issues with population sizes and actual times of divergence, not to mention generation times.
There's no point in getting your knickers in a knot at this time.

Nessa Carey doesn't understand junk DNA
Nessa Carey is a science writer with a Ph.D. in virology and she is a former Senior Lecturer in Molecular Biology at Imperial College, London.
She has written a book on junk DNA but it's not available yet (in Canada). Judging by her background, she should be able to sort through the controversy and make a valuable contribution to informing the public but, as we've already noted Nessa Carey and New Scientist don't understand the junk DNA debate.
Casey Luskin has a copy of the book so he wrote a blog post on Evolution News & Views.
Thursday, April 30, 2015
Nature reviews Nessa Carey's book on junk DNA
Finally, Junk DNA, like the genome, is crammed with repetitious elements and superfluous text. Bite-sized chapters parade gee-whizz moments of genomics. Carey's The Epigenetics Revolution (Columbia University Press, 2012) offered lucid science writing and vivid imagery. Here the metaphors have been deregulated: they metastasize through an otherwise knowledgeable survey of non-coding DNA. At one point, the reader must run a gauntlet of baseball bats, iron discs, Velcro and “pretty fabric flowers” to understand “what happens when women make eggs”. The genome seems to provoke overheated prose, unbridled speculation and Panglossian optimism. Junk DNA produces a lot of DNA junk.
The idea that the many functions of non-coding DNA make the concept of junk DNA obsolete oversells a body of research that is exciting enough. ENCODE's claim of 80% functionality strikes many in the genome community as better marketing than science.
Friday, May 8, 2016
Ford Doolittle talks about transposons, junk DNA, ENCODE, and how science should work
"There is no critique in science, very little. You can’t actually say, “This doesn’t mean what people say it means.” You’ve got to be “positive;” you’ve got to be moving the program forward all the time. I don’t think that is right."
Monday, May 11, 2016
Genomics journal is about to embarrass itself with a special issue on junk DNA
Some of you will recognize the names of the guest editors. Jim Shapiro is one of the poster boys of Intelligent Design Creationism because he attacks evolutionary theory. He's one of the founders of the "The Third Way."
You may be less familiar with Shi Huang. He is also part of the Third Way movement but we've recently learned a lot more about him because he posts comments under the name "gnomon." You can see some of his comments in this thread: Ford Doolittle talks about transposons, junk DNA, ENCODE, and how science should work. Shi Huang appears to have a great deal of difficulty expressing himself in a rational manner.
Those guest editors will publish papers that "... provide a view of evidence from a perspective that all genome regions have (or can easily acquire) functionality." In other words, skeptics need not apply.

The "Insulation Theory of Junk DNA"
There are two obvious difficulties with the insulation theory of junk DNA. The first is that Nessa Carey believes that a lot of noncoding DNA is functional. If she's correct, that requires a great deal of insulating DNA if it's going to protect the functional parts. You can't have it both ways.
The second problem is that it doesn't pass the Onion Test. (I don't think the Onion Test is mentioned in the book but I haven't finished it yet.)

Junk DNA is so last century!
That view is shared by science writer Claire Ainsworth who wrote a review in New Scientist: Its' so last century.1 Ainsworth is a freelance science writer with a Ph.D. in developmental genetics from Oxford (Oxford, UK). She is co-founder of SciConnect, a company that teaches science communication skills to scientists.
Here's what she says in her review ....

John Parrington and the genetic load argument
I've already addressed some of the fuzzy thinking in this paragraph [The fuzzy thinking of John Parrington: The Central Dogma and The fuzzy thinking of John Parrington: pervasive transcription]. The point I want to make here is that Parrington's arguments for function in the genome require a great deal of sequence information. They all conflict with the genetic load argument.
Parrington doesn't cover the genetic load argument at all in his book. I don't know why since it seems very relevant. We could not survive as a species if the sequence of most of our genome was important for biological function.
Friday, July 24, 2015
John Parrington and the C-value paradox
It's safe to say that John Parrington doesn't understand the C-value argument. We already know that Mattick doesn't understand it and neither does Jonathan Wells, who also wrote a book on junk DNA [John Mattick vs. Jonathan Wells]. I suppose John Parrington prefers to quote Mattick instead of Jonathan Wells—even though they use the same arguments—because Mattick has received an award from the Human Genome Organization (HUGO) for his ideas and Wells hasn't [John Mattick Wins Chen Award for Distinguished Academic Achievement in Human Genetic and Genomic Research].
For further proof that Parrington has not done his homework, I note that the Onion Test [The Case for Junk DNA: The onion test ] isn't mentioned anywhere in his book. When people dismiss or ignore the Onion Test, it usually means they don't understand it. (For a spectacular example of such misunderstanding, see: Why the "Onion Test" Fails as an Argument for "Junk DNA").
Friday, July 24, 2015
John Parrington and modern evolutionary theory
Nobody who understands modern evolutionary theory would ask such a question. They would have read all the published work on the issue and they would know about the limits of natural selection and why species can't necessarily get rid of junk DNA even if it seems harmful.
People like that would also understand the central dogma of molecular biology.
Five things John Parrington should discuss if he wants to participate in the junk DNA debate
It's frustrating to see active scientists who think that most of our genome could have a biological function but who seem to be completely unaware of the evidence for junk. Most of the positive evidence for junk is decades old so there's no excuse for such ignorance.
I wrote a post in 2013 to help these scientists understand the issues: Five Things You Should Know if You Want to Participate in the Junk DNA Debate. It was based in a talk I gave at the Evolutionary Biology meeting in Chicago that year.1 Let's look at John Parrington's new book to see if he got the message [Hint: he didn't].
Friday, July 24, 2015
John Parrington discusses pseudogenes and broken genes
As usual, Parrington doesn't address the big picture. Instead he resorts to the standard ploy of junk DNA proponents by emphasizing the exceptions. He devotes more that two full pages (pages 143-144) to evidence that some pseudogenes have acquired a secondary function.
The potential pitfalls of writing off elements in the genome as useless or parasitical has been demonstrated by a recent consideration of the role of pseudgogenes. ... recent studies are forcing a reappraisal of the functional role of these 'duds."Do you think his readers understand that even if every single broken gene acquired a new function that would still only account for less than 2% of the genome?

John Parrington discusses genome sequence conservation
You can't argue this way. More than 90% of our genomes is not conserved—not even between individuals. If a good bit of that DNA is, nevertheless, functional, then those functions must not have anything to do with the sequence of the genome at those specific sites. Thus, regions that specify non-coding RNAs, for example, must perform their function even though all the base pairs can be mutated. Same for regulatory sequences—the actual sequence of these regulatory sequences isn't conserved according to John Parrington. This requires a bit more explanation since it flies on the face of what we know about function and regulation.
Finally, if you are going to use bulk DNA arguments to get around the conflict then tell us how much of the genome you are attributing to formation of "3D entities." Is it 90%? 70%? 50%?
Friday, July 24, 2015
John Parrington talks about The Deeper Genome
Here's a video from Oxford Press where you can hear John Parrington describe some of the ideas in his book: The Deeper Genome: Why there is more to the human genome than meets the eye.

On the total length of all DNA molecules on the planet
Michael Lynch has a crude estimate in his book The Origins of Genome Architecture. Without reading the book, can you come up with an estimate of your own? Is it larger than the circumference of the Earth? Larger than the distance to Pluto? Longer than the distance to the nearest star (other than the sun) or the the center of the galaxy? Would the string of DNA molecules stretch to the nearest large galaxy (Andromeda)? Or, would it be even longer than that?
Wednesday, July 29, 2015
Michael Lynch on modern evolutionary theory
Here's what you need to know about evolution in order to discuss junk DNA. The first quotation is from the preface to The Origins of Genome Architecture (pages xiii-xiv). The second quotations are from the last chapter (page 366 and pages 368-369.

The next step in genomics
A massive amount of data on complex genomes has been published, especially on the human genome. The next step is to decide what this data means. Here are the most important questions from my perspective.

Insulators, junk DNA, and more hype and misconceptions
There are tRNA-derived SINES in the human genome so the authors decided to look at one particular class, called MIRs to see if they had insulator activity. Some of them are expected to have some of the characteristics of insulators because they contain the B-box sequence that serves as a binding site for RNA polymerase III. This will disrupt chromatin structure in the surrounding region as shown in Figure 1 of their paper (left).
The study identified 1,178 SINEs that could possibly be involved in an insulator-like function. Nobody knows how many of these are just defective SINES that happen to retain RNA polymerase III binding motifs but are still junk DNA. Nobody knows how many of them have been co-opted to serve a biological function in regulating expression of nearby genes. However, it's important to keep in mind that we're dealing with sequences of less than 100 bp and even if every single one of them has been co-opted to serve a biological function—an absurd possibility—it would still only amount to less that 0.01% of the genome.

Four things that Francis Collins learned from sequencing the human genome
I've been doing a bit of research on the human genome in preparation for a book. This led me to an article published in 2003 by Francis Collins, former head of the Human Genome Consortium (Collins, 2003). It's mostly about how he deals with science and religion but there was an interesting description of what he learned from completing the human genome sequence.
Tuesday, August 25, 2015
The apophenia of ENCODE or Pangloss looks at the human genome
This is a paper in French by Casane et al. (2015). Most of you won't be able to read it but the English abstract gives you the gist of the argument. I had to look up "apophenia": "Apophenia has come to imply a universal human tendency to seek patterns in random information, such as gambling."
Monday, Sept. 7, 2015
Mitochondria are invading your genome!
The human mitochondrial genome is a small circular genome of 16,570 ± 50 bp (Rubino et al., 2012). It contains only a few genes but it is still invading the nuclear genome. The average human genome contains about 600 fragments of mitochondrial DNA ranging in size from 30 bp to almost the full size of the mitochondrial genome (Simone et al. 2011). They are called NumtS or nuclear mitochondrial sequences. 1
Some of the genome inserts are 100% identical in sequence to the standard mitochondrial genome sequence indicating a recent colonization event. Others are as little as 63% identical, the cut-off similarity. The total amount of mitochondria-derived DNA in one individual was 627,410 bp amounting to only 0.02% of the genome (Simone et al., 2011).
Wednesday, Sept. 9, 2015
Major advances in genome biology
I recently stumbled on a paper with an intriguing title" "Sixty years of genome biology" (Doolittle et al., 2013). It celebrates the 60th anniversary of the Watson & Crick paper on the structure of DNA. The editors of Genome Biology describe key advances in genome biology.
Sunday, Sept. 20, 2015
Does genome size affect fitness in seed beetles?
I don't find the evidence convincing. Furthermore, even if there were a genuine correlation between genome size and reproductive fitness in this species of seed beetle, I don't think you can reasonably extrapolate this to onions.
None of the explanations make much sense and one of them (telomere length) is silly. I recognize that you don't need an explanation if the data is true—"unknown" is an acceptable answer—but we know enough about genomes and molecular biology to say that a cause and effect relationship is unlikely.

How many RNA molecules per cell are needed for function?
When you have a situation where a regulatory RNA has to bind to a small number of mRNAs in a cell, the binding and kinetic parameters determine the concentration of the regulatory RNA required to get significant regulation. The values of the constants they determined are quite reasonable so it serves as a good standard to judge the concentrations needed for regulation. Fei et al. concluded that in E. coli cells you need about 1000 molecules of the regulatory RNA per cell in order to regulate the mRNAs.
This number has to be larger in eukaryotic cells because the cells are bigger and there are more mRNA molecules dispersed in the cytoplasm. The results strongly suggest that most of the transcripts detected are present at too low a concentration to be effective in regulation by binding to mRNA.
Sunday, Oct. 4, 2015
Genetic variation in human populations
Given those limitations, the results of the studies are very informative. Looking at single base pair changes and small indels (insertions and deletions), the typical human genome (yours and mine) differs from the standard reference genome at about 4.5 million sites. That's about 0.14% of our genomes. Humans and chimpanzees differ by about 1.4% or ten times more.
SNPs and small indels account for 99.9% of variants. The others are "structural variants" consisting of; large deletions, copy number variants, Alu insertions, LINE L1 insertions, other transposon insertions, mitochondrial DNA insertions (NUMTS), and inversions. The typical human genome has about 2,300 of these structural variants of which about 1000 are large deletions.
Most of these variants are in junk DNA regions but the typical human genome carries about 10-12,000 variants that affect the sequence of a protein. Many of these will be neutral and some of the ones that have a detrimental effects will be heterozygous and recessive. The average person has 24-30 variants that are associated with genetic disease. (These are known detrimental alleles. If you get your genome sequenced, you will learn that you carry about 30 harmful alleles that you can pass on to your children.)
Friday, Oct. 16, 2015
Human mutation rates
But let's think about the mutation rate. The value of ~60 new point mutations per generation in Shendure and Akay (2015) is quite a bit lower than the number I prefer (>100). My estimate is based on my understanding of the scientific literature. I've discussed this before in Human mutation rates - what's the right number?. The discussion in the comments section of my post is very enlightening; it reveals that the issue is complicated and all estimates, by any method, are open to criticism.
Shendure and Akay gave us four references to support their claim that the rate is ~60 mutations per generation.
Sunday, Nov. 1, 2015
3,000 new genes discovered in the human genome - dark matter revealed
The authors claim that their complete annotation database contained 18,268 lncRNA "genes." I don't know of any reliable annotation of the human genome that includes as many as 18,000 lncRNA genes. The latest ENSEMBL version [GRCh38.p3 (Genome Reference Consortium Human Build 38] has 14,898 and that's a very generous (and incorrect) count of "genes."
One of the good things about this paper is that the authors include data on the expression levels of their putative genes. One of the bad things about this paper is that they follow the example of many other authors by converting the data into something called "FKPM." It turns out that 80% of their novel lncRNA "genes" are expressed at an FPKM > 1 in at least one cell type. (I don't know exactly what that means in terms of transcripts per cell but I think it's about one transcript per cell or less.)
The most important part of this study should have been providing evidence for their claim that the new transcripts are functional and therefore that the complementary DNA sequences are actually genes. This would require a discussion of what a "gene" is and it would require that the authors refer to their transcripts as putative lncRNAs and the DNA sequences as "possible genes." They don't do that.

More stupid hype about lncRNAs
I've just posted an article about a group of scientists at UCLA who claimed to have discovered 3,000 new genes in the human genome [3,000 new genes discovered in the human genome - dark matter revealed].
They did no such thing. What they discovered was about 3,000 previously unidentified transcripts expressed at very low levels in human B cells and T cells. They declared that these low-level transcripts are lncRNAs and they assumed that the complementary DNA sequences were genes. Their actual result identifies 3,000 bits of the genome that may or may not turn out to be genes. They are PUTATIVE genes.
None of that deterred Karen Ring who blogs at The Stem Cellar: The Official Blog of CIRM, California's Stem Cell Agency.

The birth and death of salmon genes
There were able to get reliable data on 9,040 of the original genes in the ancestral genome. (That's about one third of the estimated 31,000 genes in the genome of the original species.) Of those 9,040 genes, 4,728 (52%) are now single copy genes because one of the duplicated genes has been lost. Many of these original genes are still detectable as pseudogenes at the right position in the genome.
By combining these results with studies of more ancient genome duplications in the vertebrate lineage, it looks like the average rate of gene loss is about 170 genes per million years (Berthelot et al., 2004). It's likely that in the majority of cases one of the duplicates will eventually become inactivated by mutation and that allele will become fixed in the genome by random genetic drift. (Some early inactivation events may be selected.)
Friday, Nov. 6, 2015
The cost of a new gene
Michael Lynch and Georgi Marinov (Hi, Georgi!) have just published a paper where they attempt to calculate the cost of adding DNA as well as the cost associated with transcribing that DNA and translating it into protein (Lynch and Marinov, 2015). One of the goals of the paper is to figure out the overall selective advantage of a new gene given that its product might confer selective advantage when there's an energy cost—in ATP equivalents—associated with every new gene.
Monday, Nov. 9, 2015
How many proteins do humans make?
According to Kim et al. there are still several thousand potential protein-coding genes that have not been confirmed by detecting a protein product. In addition, they found 44 new ORFs that have not been annotated in the latest release of the human genome. These are potential new genes but the authors caution that the proteins may not have a function. Only 144 pseudogenes produced a polypeptide out of about 15,000 in the human genome. This is not unexpected since recently inactivated genes might still produce nonfunctional protein or protein fragments. It reminds us that cells can produce junk proteins as well as junk DNA.
The other group looked at mass-spec data that had been published in the past ten years. A total of from 27 different tissues were examined(Wilhelm et al, 2015). They constructed a database (ProteomicsDB) that accounted for 18,097 protein-coding genes out of the total of 19,629 that were annotated in the Swiss-Prot database. This accounts for almost all of the potential protein-coding genes. (Some genes might be expressed in very restricted cells at very limited times during development. Other genes produce proteins that can't be detected by the techniques used in most studies. Other "genes" might actually be pseudogenes.)
Wednesday November 18, 2015
Different kinds of pseudogenes - are they really pseudogenes?
A pseudogene is a broken gene that cannot produce a functional RNA. They are called "pseudogenes" because they resemble active genes but carry mutations that have rendered them nonfunctional. The human genome contains about 14,000 pseudogenes related to protein-coding genes according to the latest Ensembl Genome Reference Consortium Human Genome build [GRCh38.p3]. There's some controversy over the exact number but it's certainly in that ballpark.
Wednesday November 18, 2015
Different kinds of pseudogenes: Processed pseudogenes

Let's look at the formation of a "processed" pseudogene. They are called "processed" because they are derived from the mature RNA produced by the functional gene. These mature RNAs have been post-transcriptionally processed so the pseudogene resembles the RNA more closely than it resembles the parent gene.
This is most obvious in the case of processed pseudogenes derived from eukaryotic protein-coding genes so that's the example I'll describe first.
Friday, November 20, 2015
Different kinds of pseudgogenes: Duplicated pseudogenes
Of the three different kinds of pseudogenes, the easiest kind of pseudogene formation to understand is simple gene duplication followed by inactivation of one copy. [see: Processed pseudogenes for another type]
I've assumed, in the example shown below, that the gene duplication event happens by recombination between sister chromosomes when they are aligned during meiosis. That's not the only possibility but it's easy to understand.
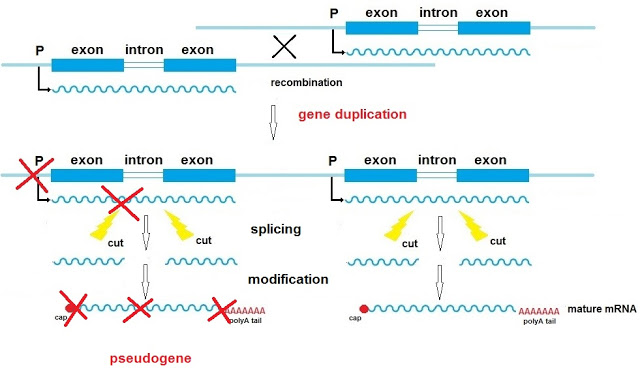
Friday, November 20, 2015
Different kinds of pseudogenes: Unitary pseudogenes
The most common types of pseudogenes are processed pseudogenes and those derived from gene duplication events [duplicated pseudogenes].
The third type of pseudogene is the "unitary" pseudogene. Unitary pseudogenes are genes that have no parent gene. There is no functional gene in the genome that's related to the pseudogene.
Unitary psedogenes arise when a normally functional gene becomes inactivated by mutation and the loss of function is not detrimental to the organism. Thus, the mutated, inactive, gene can become fixed in the population by random genetic drift.
Friday, November 20, 2015
Different kinds of pseudogenes: Polymorphic pseudogenes
There are three main kinds of pseudogenes: processed pseudogenes, duplicated pseudogenes, and unitary pseudogenes [Different kinds of pseudogenes - are they really pseudogenes?].
There's one sub-category of pseudogenes that deserves mentioning. It's called "polymorphic pseudogenes." These are pseudogenes that have not become fixed in the genome so they exist as an allele along with the functional gene at the same locus. Some defective genes might be detrimental, representing loss-of-function alleles that compromise the survival of the organism. Lots of genes for genetic diseases fall into this category. That's not what we mean by polymorphism. The term usually applies to alleles that have reached substantial frequency in the population so that there's good reason to believe that all alleles are about equal with respect to natural selection.

The truth about ENCODE
Back in September 2012, the ENCODE Consortium was preparing to publish dozens of papers on their analysis of the human genome. Most of the results were quite boring but that doesn't mean they were useless. The leaders of the Consortium must have been worried that science journalists would not give them the publicity they craved so they came up with a strategy and a publicity campaign to promote their work.
Sunday, November 22, 2015
What do pseudogenes teach us about intelligent design?
The presence of a single well-characterized pseudogene at the same locus in the genomes of different species is powerful evidence of common descent. For example, Ken Miller has long argued that the existence of common pseudogenes in chimpanzees and humans is solid evidence that the two species share a common ancestor. He uses the β-globin pseudogene and the gene for making vitamin C as examples in Only a Theory: Evolution and the Battle for America's Soul.

Selfish genes and transposons
Some scientists were experts in modern evolutionary theory but still wanted to explain "junk DNA." Doolittle & Sapienza, and Orgel & Crick, published back-to-back papers in the April 17, 1980 issue of Nature. They explained junk DNA by claiming that most of it was due to the presence of "selfish" transposons that were being selected and preserved because they benefited their own replication and transmission to future generations. They have no effect on the fitness of the organism they inhabit. This is natural selection at a different level.

Motoo Kimura calculates a biochemical mutation rate in 1968
I recently had occasion to re-read a paper by Motoo Kimura from 1968. (Kimura, 1968). I noticed, for the first time, that he estimates a mutation rate based on his understanding of the error rate of DNA replication. He also makes a comment about creationists.
Remember, this was in 1968 and we didn't know as much then as we do now. Kimura took note of the fact that evolutionary trees based on comparing amino acid sequences gave rates of amino acid substitutions that seemed far too high.
Wednesday, December 9, 2015
Why doesn't natural selection reduce the mutation rate to zero?
All living organisms have developed highly accurate DNA replication complexes and sophisticated mechanisms for repairing DNA damage. The combination results in DNA replication errors that are about 1 per 10 billion base pairs (10-10 per bp). DNA damage due to other factors is effectively repaired with an error rate of 1 in 100 per base pair (10-2 per bp).
Mutations can be beneficial, deleterious, or neutral. In organisms with large genomes there are many more neutral mutations than the other two classes but in organisms with smaller genomes a higher percentage of mutations are either beneficial or deleterious. In all cases, there are more deleterious mutations than beneficial ones
Thursday, December 10, 2015
How many human protein-coding genes are essential for cell survival?
The human genome contains about 20,000 protein-coding genes and about 5,000 genes that specify functional RNAs. We would like to know how many of those genes are essential for the survival of an individual and for long-term survival of the species.
It would be almost as interesting to know how many are required for just survival of a particular cell. This set is the group of so-called "housekeeping genes." They are necessary for basic metabolic activity and basic cell structure. Some of these genes are the genes for ribosomal RNA, tRNAs, the RNAs involved in splicing, and many other types of RNA. Some of them are the protein-coding genes for RNA polymerase subunits, ribosomal proteins, enzymes of lipid metabolism, and many other enzymes.
Tuesday, December 15, 2015
How many different proteins are made in a typical human cell?
I suspect that Küster is one of those scientists who think that almost all human protein-coding genes are alternatively spliced to yield several different proteins in each cell. He has to imagine that there are, on average, ten different versions of a protein produced from each gene that's expressed in a typical cell.
That means ten different versions of each of the subunits of pyruvate dehydrogenase and RNA polymerase. It means ten different versions of triose phosphate isomerase and each of the ribosomal proteins. There should be ten different versions of actin and ten different versions of cytochrome c.
This seems very unlikely to me.
Saturday January 18, 2016
Brandeis professor demonstrates his ignorance about junk DNA
Lau was interviewed by Lawrence Goodman, a science communication officer at Brandeis University: DNA dumpster diving. The subject is junk DNA and you will be astonished at how ignorant Nelson Lau is about a subject that's supposed to be important in his work.
How does this happen? Aren't scientists supposed to be up-to-date on the scientific literature before they pass themselves off as experts? How can an Assistant Professor make such blatantly false and misleading statements about his own area of research expertise? Has he never encountered graduate students, post-docs, or mentors who would have corrected his misconceptions?
Sunday, January 19, 2016
Nelson Lau responds to my criticism of his comments about junk DNA
I criticized Nelson Lau for comments he made about the junk DNA debate [Brandeis professor demonstrates his ignorance about junk DNA].
Here is his response,
Sunday, January 17, 2016
Origin of de novo genes in humans
In spite of what you might have read in the popular literature, there are not a large number of newly formed genes in most species. Genes that appear to be unique to a single species are called "orphan" genes. When a genome is first sequenced there will always be a large number of potential orphan genes because the gene prediction software tilts toward false positives in order to minimize false negatives. Further investigation and annotation reduces the number of potential genes.
The human genome has a number of duplicated genes that aren't found in our closest relatives but, for the most part, these are transient duplications and the extra gene will soon be deleted or disabled (it becomes a pseudogene). The interesting new genes are de novo genes—new genes that are not derived from a gene duplication event. There are about 60 potential de novo genes in our genome [see How many genes do we have and what happened to the orphans?].

All about Craig
The second sequence was from Celera Genomics, led by Craig Venter. It was mostly his genome, making him the second being to know his own instruction book ... right after God.
It took another seven years to finish and publish the complete sequence of all of Craig Venter's chromosomes. The paper was published in PLoS Biology (Levy et al., 2007) and highlighted in a Nature News article: All about Craig: the first 'full' genome sequence.
What's unique about this genome sequence—other than the fact that it's God's Craig Venter's—is that all 46 chromosomes were sequenced. In other words, enough data was generated to put together separate sequences of each pair of chromosomes. That produces some interesting data.
Wednesday, January 20, 2016
Bryony Graham: another scientist who writes about the junk DNA controversy without doing her homework
I was searching for information about Craig Venter and his position on junk DNA when I stumbled upon this post by Bryony Graham: Why we still don’t have personalised medicine, 15 years after sequencing the human genome. She is a postdoc in Molecular Genetics at the University of Oxford so the subject is within her area of expertise.1
The post is from Dec. 1, 2015—that's only one month ago so she should be aware of all the facts concerning junk DNA.
Tuesday, February 9, 2016
Junk DNA doesn't exist according to "Conceptual Revolutions in Science"
It's not obvious to me how this qualifies him to be the judge of shifting paradigms in science but maybe he's just very good at choosing the right authors and advisers.
Let's see how this works. The article published on Feb. 7, 2016 looks interesting. It's title is Epigenetic News, How Long Noncoding RNA Can Regulate Colon Cancer. The "paradigm shifting" news is "How junk DNA actually regulates colon cancer."
That's pretty interesting, isn't it? The article was written by Nicholas Morano (@nickmorano) who is working on a Ph.D. in biochemistry at Albert Einstein College of Medicine, Yeshiva University, in New York (USA). Here's the first two paragraphs,

Happy birthday human genome sequence!
The draft sequences of the human genome were published fifteen years ago. The International Human Genome Project (IGHP) published its draft sequence in Nature on Feb. 15, 2001 (Lander et al., 2001) and Celera Genomics published its draft sequence in Science on Feb. 16, 2001 (Venter et al., 2001).1
For me the timing was perfect since I was scheduled to give a Journal Club talk on March 16th and you could hardly ask for a better topic.

When philosophers talk about genomes
Postgenomics is a compendium of twelve scholarly articles by philosophers and sociologists who write about the implication of the human genome sequence and subsequent work on interpreting the results. The volume is edited by Sarah Richardson, a professor in Social Sciences (History of Science) at Harvard University (Boston, Massachusetts, USA), and by Hallam Stevens, a professor of History at Nanyang Technology University in Singapore (Singapore).
Wednesday, March 9, 2016
A 2004 kerfuffle over pervasive transcription in the mouse genome
Wang et al. (2004) decided to look at the 15,815 TUs that could potentially be genes for noncoding RNAs. Remember that there is considerable debate over the number of genes for functional noncoding RNAs. The ENCODE Consortium claims that pervasive transcription of the human genome indicates that it is full of such genes and they play a key role in regulating the expression of protein-coding genes.
Back in 2004, there were just as many skeptics as there are today. Wang et al. examined the potential genes to see if they were any more conserved than random DNA intergenic sequences in the mouse genome. If they represent randomly transcribed regions of the genome that produce junk RNA by accidental transcription then you expect them to be evolving at the neutral rate whereas if they really are genes for functional RNAs then you expect them to show evidence of sequence conservation.
Sunday, March 13, 2016
Paradigm shifting
I was reading up on non-coding RNAs and came across this recent paper.
Bhartiya, D., and Scaria, V. (2016) Genomic variations in non-coding RNAs: Structure, function and regulation. Genomics 107:59-68. [doi: 10.1016/j.ygeno.2016.01.005]
Abstract: The last decade has seen tremendous improvements in the understanding of human variations and their association with human traits and diseases. The availability of high-resolution map of the human transcriptome and the discovery of a large number of non-protein coding RNA genes has created a paradigm shift in the understanding of functional variations in non-coding RNAs. Several groups in recent years have reported functional variations and trait or disease associated variations mapping to non-coding RNAs including microRNAs, small nucleolar RNAs and long non-coding RNAs. The understanding of the functional consequences of variations in non-coding RNAs has been largely restricted by the limitations in understanding the functionalities of the non-coding RNAs. In this short review, we outline the current state-of-the-art of the field with emphasis on providing a conceptual outline as on how variations could modulate changes in the sequence, structure, and thereby the functionality of non-coding RNAs.

Another failure: "The Mysterious World of the Human Genome"
This is just another "gosh, gee whiz" book on the amazing and revolutionary (not!) discoveries about the human genome. The title tells you what to expect: The Mysterious World of the Human Genome.
The author is Frank P. Ryan, a physician who was employed as an "Honorary Senior Lecturer" in the Department of Medical Education at the University of Sheffield (UK). He's a member of The Third Way group. You can read more about him at their website:

Teaching about genomes using Nessa Carey's book: Junk DNA
Nessa Carey's book about junk DNA is an embarrassment to the scientific community [Nessa Carey doesn't understand junk DNA] [The "Insulation Theory of Junk DNA"].
Today, while searching for articles on junk DNA, I came across a review of Nessa Carey's book published in The American Biology Teacher: DNA. The review was written by teacher in Colorado and she liked the book very much.

Georgi Marinov reviews two books on junk DNA
The December issue of Evolution: Education and Outreach has a review of two books on junk DNA. The reviewer is Georgi Marinov, a name that's familiar to Sandwalk readers. He is currently working with Michael Lynch at Indiana University in Bloomington, Indiana, USA. You can read the review at: A deeper confusion.
The books are ...
The Deeper Genome: Why there is more to the human genome than meets the eye, by John Parrington, (Oxford, United Kingdom: Oxford University Press), 2015. ISBN:978-0-19-968873-9.
Junk DNA: A Journey Through the Dark Matter of the Genome, by Nessa Carey, (New York, United States: Columbia University Press), 2015. ISBN:978-0-23-117084-0.

The Encyclopedia of Evolutionary Biology revisits junk DNA
Ludwig seems to be arguing that a significant fraction of the mammalian genome is devoted to regulation. He doesn't ever specify what this fraction is but apparently it's large enough to "revisit" junk DNA.

What is a "gene" and how do genes work according to Siddhartha Mukherjee?
I think it's time to stop being surprised by the fact that some species might have more genes than we do and time to explain why some plants might have more genes. And it's time to stop saying that humans might have a more sophisticated way of controlling their genes. Non-experts5 might have been surprised by the low number of genes back in 2001 but that was 15 years ago. Get over it.
If your ego has been deflated by the fact that we don't have lots more genes than breakfast cereal, then you'd better come up with an explanation other than the fact that you just don't understand evolution. I listed the seven most common rationalizations. One of them is alternative splicing. Another is "sophisticated" and highly precise gene regulation. Mukherjee goes part way down the path of using some of these rationalizations to explain his disappointment at our low number of genes ....
2 comments :
it's great material...
your blog will make me to improve my biology
thanks...
By:
http://biology-community.blogspot.com/
Advancing Genomics Mandates Prior Rethink-Update Of Genetics
On “Time’s Arrow” and on “Genetic Mutation Rate”
A. Evolution Points Time’s Arrow
http://universe-life.com/2013/01/09/randomness-is-impossible-in-the-universe/
An evolving system EVOLVES continuously, without randomness. The universe evolves, cyclically, between its all mass pole and all energy pole.
Period.
B. A Genetic Mutation Rate???
http://news.sciencemag.org/sciencenow/2013/03/clocking-the-human-exodus-out-of.html?ref=em
Exasperating ignorance.
Genetics is THE PROGENY of culture.
Genes (and genomes) are organisms, molded (i.e. are expressions modified) via natural selection by their reactions to their circumstances (i.e. by their culture).
Look up Pavlov and Darwin…
Respectfully,
Dov Henis
http://universe-life.com
My Don Quixotic mission: Un-theosophize religious “Science” of trade-union-church AAAS.
Genetics is modifications of genome’s expressions in response to cultural variations, which is behavioral modifications in response to circumstantial variations. DH
Post a Comment