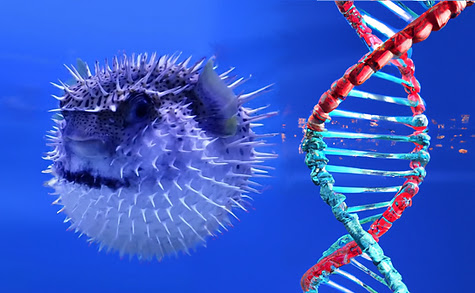
Raphaël Champeimont has a blog called The Purple Blog: Freedom and Technology. His latest post is called The great Pufferfish Genome and it's well worth a read. Here's an excerpt ...
Human: I am the mighty human, pinnacle of the evolution: I have the most advanced and complex genome with 25,000 genes and an impressive 3 billion base pairs in my DNA, you know these letters like A, T, G, C which make my genome. 3 billion of them!
Pufferfish: Come on. Your genome is just full of junk, 90% of it is completely useless! It’s full of dead viruses that infected your ancestors long ago and you never cleaned it up. Look at my genome, I have just as many genes as you, but I don’t need to waste 3 billion base pairs of DNA for that, just 400 million is well enough. Yes, I pack as many genes as you in a genome 10 times smaller! That’s what I call optimization!
I met Raphaël a few months ago at a Café Scientific meeting in Mississauga, Ontario (Canada) and he came to our meeting last night. Turns out, he read my book and that's why he posted an article about genomes.
I recently read a very interesting new book “What's in Your Genome? 90% of Your Genome Is Junk” by Laurence A. Moran, in which he argues that our knowledge of genomics points to the fact that 90% of the human genome is useless junk.
This idea is not new, but it has become unfashionable in the last 20 years, without good evidence, the author argues. Most of our genome is still junk, and a central argument is that many other species don’t need that much DNA, or have much more without any “good” reason like the organism’s complexity.
I've lost count of how many people have read my book. I think this makes six or maybe seven!
19 comments :
I not only have read it, but I believe you are correct, and I have written about junk DNA based on your book and found that for the first time I had to have a part 1 and part 2!
https://www.truthfulorigins.info/post/junk-dna-and-encode-part-1
I understand why onions, humans, and lungfish can have enlarged genomes full of various amounts of junk DNA. This being the result of neutral genetic drift. Meanwhile, the small genomes of yeast is also explainable, since their microbial ecology is one of tight energy budgets and short generation times. But why would the Pufferfish have a reduced genome? I can't think of a reason other than that genetic drift is "drifty". Sometimes drift wanders downward more than upward.
While I agree with you and Raphaël I have problems with the DNA which seemingly changes from left- to right-handed in the displayed picture.
Ahah that's an AI-generated picture and it did not get it fully correct indeed.
The presence of large amounts of junk DNA is neutral in the sense that natural selection is ineffective in reducing it. It is ineffective in effectively opposing forces such as infection of the genome by transposons. Just saying "the result of genetic drift" makes it sound like a base was added here and there by accident and piled up to be vast amounts of junk DNA. Correct me if I'm wrong, Larry, but spread of a transposon family is not like that at all.
@Joe Felsenstein
Genomes can expand in size by segmental duplication or transposon insertion, among other things. In both cases, a new allele is created with extra DNA that was not present in the original genome at that locus.
The fate of that new allele in the population is determined by selection or genetic drift. If the new allele is effectively neutral then it could become fixed by random genetic drift.
@Larry: It was my understanding that active transposons infect both haploid genomes and therefore have a 2x advantage, which is strong genomic drive (or "meitoic drive") in their favor. Much more rapid spread in the population than mere drift.
... and in addition of course, once an active transposon is in a genome, it makes copies of itself at other places on both haploid genomes. So in effect it creates mutations to itself.
Let me be more accurate: meiotic drive systems may copy a stretch of chromosome to all gametes, rather than the 1/2 of them that normal Mendelian segregation does. Active transposons result in an increase of copies in all the gametes, though located in many different parts of the genome. Considered for the whole genomes of descendants, an increase of copies far faster than would occur just by genetic drift, with the loss of the transposon from the genome much less likely than with mere genetic drift.
Dr. Moran....I finally finished your junk science book!
Don't misunderstand. I mean: it's about junk (nuclear), junk science (ENCODE et al) and it is a science book (molecular biology primer). I found it factual, entertaining and educational. (Hell, impressed me enough that I think I'll buy your textbook!)
However, being a biochem novice (not having read your textbook), I have some (possibly dumbass) questions about junk and genomes: (question first, then rationale for question) length constraints => multiple posts.
Q1 Re: Enzyme count vs protein count. As you note, trying to find out if a random protein is functional and trace its origin back to some stretch of DNA is not a job most scientists would take on, so it may be a long time before there is a good functional protein count. However, lots of biochemists are already motivated to study enzymatic reactions (I understand that they write papers and get paid well by industry for this sort of thing.) Shouldn't it be easier to refute the overly-high enzyme count rather than the total protein count, thereby calling into question the overall functional protein count?
(Bonus for counting enzymes: Tracking the enzyme count should also motivate the non-junk proponents who would have a way to invalidate the null hypothesis: simply find and verify enough human enzymes to get the verified count greater than about 25,000.)
Q1 Rationale: It is widely believed that we make 100,000 different proteins using only 20,000 genes. I see on popular science internet sites that estimates for enzymes alone of up to 75,000 are common. However, at least two sites that actually catalogue enzymes, "the Enzyme Commission" and the "brenda-enzymes.org database", show enzyme counts of only about 6,500. I understand that the EC requires a verified reaction mechanism before an entry can be added to its DB, which would account for a more realistic, verified count.
Q2: Re: Selection for fitness at the DNA level. Would it count as selection for fitness at the DNA level if the cellular components of one sex in a cell test their compatibility with those of the other sex in the same cell? Or is the example given in the rationale, below, just normal selection?
Q2 Rationale: Nick Lane in his book, The Vital Question, notes: "One of the deepest distinctions between the two sexes relates to the inheritance of mitochondria – one sex passes on its mitochondria, while the other sex does not." Perhaps, then, there is... " a requirement for mitochondrial genes to adapt to genes in the nucleus. " He speculates that, just after fertilization, nuclear DNA instructs the mitochondria to run "flat out" as a stress test. If they can't perform in concert with the nucleus they go into distress, trigger apoptosis, and the embryo dies.
Q3: Re: our Vitamin C gene is inactive. In theory, would it be easy or hard to reactivate our dormant vitamin C producing gene?
Q3 Rationale: Just for fun.
Q4: Re: Hypothesis: transposons promote transcription. Was there an explanation of the anti-junk Drosophila example given in your book?
Q4 Rationale: Proponents argue that there are several dozen transposons in Drosophila that affect transcription of nearby genes.
Q5: Re: Non-Conserved Spacer DNA. I'm confused about whether spacer DNA is junk or not. It is not conserved, but necessary; doesn't this mean it is necessarily conserved junk? That is, if lost, won't function be impaired?
Q5 Rationale: You note that spacer DNA (not conserved) is DNA that’s required to keep some functional regions apart. The most obvious example is the DNA in introns that’s necessary to form a loop between the splice sites.
Q6-A: Re: A Problematic Spliceosome? Is the evolutionary change from entities that automatically splice themselves out of the genome in prokaryotes, to entities where the removal mechanism has been moved into the spliceosome (and is restricted to removing introns from pre-mRNA) the root cause of accumulation of junk in eukaryotes, i.e., introns don't jump out in eukaryotes?
Q6-B: As you note, the spliceosome can miss weak splicing sites or sites masked by repressors - something that can't happen in the prokaryotes. Is this actually an evolutionary advantage for eukaryotes: that is, greater flexibility of the spliceosome/repressor/activator system to extract RNA for functional products at the appropriate time and place?
Q6 Rationale: From Vital Question (again) re: mobile introns: Introns seem to be derived from parasitic DNA elements found in bacterial genomes. The bacterial parasite ... splices itself out to form an excised intron sequence encoding a reverse transcriptase that can convert copies of the parasitic genes into DNA sequences and insert multiple copies into the bacterial genome. The eukaryotic spliceosome ... is a large protein complex, but its function depends on a catalytic RNA (ribozyme) at its heart, which shares exactly the same mechanism of splicing. This suggests that the spliceosome, and by extension eukaryotic introns, are derived from mobile group II self-splicing introns released from the bacterial endosymbiont early in eukaryotic evolution. The spliceosome is a eukaryotic machine based on a bacterial parasite.
Q7: Re: Binding Proteins. Is the amount of binding protein required proportional to total DNA content, including junk, or do weakly bound BPs pop on and off junk until they engage a functional binding site? I'm wondering about the burden of producing surplus BPs to service mostly junk. (Maybe it's not an issue as cells seem to be able to recycle most everything pretty efficiently?)
Q7 Rationale: DNA binding proteins will bind to random DNA sequences. Part of this nonfunctional binding = very weak binding to any random sequence of DNA, but mostly to sequences identical to the normal, functional binding site - lots of these because typical transcription factor binding sites are quite short. => lots of binding proteins req'd.
Q8: Re: RNA polymerase over-run in high junk and low junk eukaryotes. Is there less evolutionary pressure for strong terminators when there is lots of junk? That is, lots of runway between genes so less evo pressure over time for strong terminators? What about the low-junk eukaryote species - do they have stronger terminators or, maybe, more antisense RNA RISCs to block overruns? Do they have more critical problems with over-runs, or do over-runs not cause problems for them because, maybe, excess production from adjacent genes is not harmful? Does weak termination correlate with weak promotion, i.e. , not found for the ~ 5% of strong promotor sites?
Q8 Rationale: you note, "transcription termination in eukaryotes is a very sloppy process. The consequences of run-on transcription are much less severe in eukaryotes because genes are farther apart, and RNA polymerase can easily run over a transcription termination site and keep going for a long time before it runs into a new gene. "
Q9: Re: Deflated ego problem. Were you exaggerating for emphasis with this term or do you really think that this is a problem? Isn't the junk avoidance bias more likely due to thinking that there is a huge energy penalty to junk, leading to reduced fitness; and/or thinking that evolution, while random, would just not be quite so random - that it would have developed better error correction over billions of years? (However, when I think about possible error correction schemes, I can't come up with one that would not require way more energy/resources than just letting junk accumulate.)
Q9 Rationale: When looking at plant genome literature I saw "energy cost" as a popular rationale for looking for a correlate or putative selective agent that would explain genome size variation. [FYI, One paper on mustard clades (Ann Bot 2021 Jun4, doi 10.1093/aob/mcah028) had a short review section summarizing 18 hypothesized relations from 75 papers attempting to predict genome size. Ten hypotheses had mixed or no-effect results, and positive correlations for 4 others were contradicted by negative correlations for 4 related ones. Just the sort of result to be expected from the null hypothesis, but not acknowledged.]
(I'm done!)
@John Janis: I'm glad you enjoyed my book.
I don't have time to answer all your questions. Is there one that's more important than the others?
Not really, although I am very curious about the maximum enzyme count. I would think that there can't be too many more in hiding.
The other questions are things that came to mind as I worked through your book. They can keep.
Cheers,
JJ
P.S., Any chance you will give a talk on your book at a Mississagua Café Scientifique meeting in the near future?
https://www.nature.com/articles/d41586-024-01567-7
A species of fork fern, Tmesipteris oblanceolata, has the biggest genome ever recorded. It contains 160 billion base pairs — 11 billion more than the previous record holder, the flowering plant Paris japonica, and 50 times more than the human genome. It’s not known why the fern evolved that way, or how it accesses the relatively small proportion of DNA that is actually useful. “It’s like trying to find a few books with the instructions for how to survive in a library of millions of books — it’s just ridiculous,” says evolutionary biologist Ilia Leitch, who co-discovered the giant genome. Explaination for the fork fern’s large genome: it might be neither detrimental nor particularly helpful for the plant’s ability to survive and reproduce, so the fork fern has gone on accumulating base pairs over time, says Julie Blommaert, a genomicist at the New Zealand Institute for Plant and Food Research in Nelson.
Nature | 4 min read
Reference: iScience paper
Post a Comment