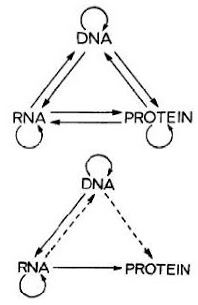
The Central Dogma of molecular biology states ...
... once (sequential) information has passed into protein it cannot get out again (F.H.C. Crick, 1958).
The central dogma of molecular biology deals with the detailed residue-by-residue transfer of sequential information. It states that such information cannot be transferred from protein to either protein or nucleic acid (F.H.C. Crick, 1970).
This is not difficult to understand since Francis Crick made it very clear in his original 1958 paper and again in his 1970 paper in Nature [see Basic Concepts: The Central Dogma of Molecular Biology]. There's nothing particularly complicated about the Central Dogma. It merely states the obvious fact that sequence information can flow from nucleic acid to protein but not the other way around.
So, why do so many scientists have trouble grasping this simple idea? Why do they continue to misinterpret the Central Dogma while quoting Crick? I seems obvious that they haven't read the paper(s) they are referencing.
I just came across another example of such ignorance and it is so outrageous that I just can't help sharing it with you. Here's a few sentences from a recent review in the 2020 issue of Annual Reviews of Genomics and Human Genetics (Zerbino et al., 2020).
Once the role of DNA was proven, genes became physical components. Protein-coding genes could be characterized by the genetic code, which was determined in 1965, and could thus be defined by the open reading frames (ORFs). However, exceptions to Francis Crick's central dogma of genes as blueprints for protein synthesis (Crick, 1958) were already being uncovered: first tRNA and rRNA and then a broad variety of noncoding RNAs.
I can't imagine what the authors were thinking when they wrote this. If the Central Dogma actually said that the only role for genes was to make proteins then surely the discovery of tRNA and rRNA would have refuted the Central Dogma and relegated it to the dustbin of history. So why bother even mentioning it in 2020?
Crick, F.H.C. (1958) On protein synthesis. Symp. Soc. Exp. Biol. XII:138-163. [PDF]
Crick, F. (1970) Central Dogma of Molecular Biology. Nature 227, 561-563. [PDF file]
Zerbino, D.R., Frankish, A. and Flicek, P. (2020) "Progress, Challenges, and Surprises in Annotating the Human Genome." Annual review of genomics and human genetics 21:55-79. [doi: 10.1146/annurev-genom-121119-083418]
















{kind=link}
{kind=link}