Triose phosphate isomerase (TIM) is one of the enzymes in the gluconeogenesis pathway leading to the synthesis of glucose from simple precursors. It also plays a role in the degradation of glucose (glycolysis). The enzyme catalyzes the following reaction ....


To the best of my knowledge, no significant variants of this enzyme due to alternative promoters, alternative splicing, or proteolytic cleavage are known.1 The enzyme has been actively studied in biochemistry laboratories for at least eighty years.
The official name of the human TPI gene is TPI1. The official database entry for this gene is maintained in a database at the American National Center for Biotechnology Information (NCBI) [Gene = 7167]. That record lists three variants produced by alternative splicing and differential use of promoters. Each of these three variants are supported by RefSeq entries. (The RefSeq entries begin with "NP" for amino acid sequences and "NM" for nucleotide sequences.)
The human version of this gene has seven exons and six introns.

The middle version of this group (isoform 2) encodes a protein of 249 amino acid residues beginning with MAPSRKFFV .... The predicted molecular weight is 26,669 daltons. The size and sequence of this version of the protein corresponds to all of the entries in the structural databases and all the data in the biochemical literature. There's no doubt that this version is a biologically relevant enzyme found in humans. This version also corresponds the the homologues in all other species.
The top version of this gene (isoform 1) corresponds to a transcript beginning from an upstream promoter. Translation of the mature mRNA is predicted to begin at a presumed start codon upstream of the normal one. This is predicted to give a protein with an extra 37 amino acid residues at the N-terminal end of the gene. This is the "canonical" sequence shown in the UniProt database [UniProt = P60174]. All other sequences are listed as variants relative to that sequence. Thus, the correct version is a "variant" missing residues 1-37.
The bottom version shown in the UniGene figure is an alternatively spliced isoform (isoform 4) missing residues 1-119. It makes no sense to suggest that this isoform has any biological significance. Isoform 3 was a version truncated at the C-terminus of the protein. It has been eliminated by curation. (Twelve other incorrect versions were eliminated many years ago.)
What about isoform 1, the version with the extra 37 amino acid residues? Is there any evidence that this protein actually exists in a biologically relevant form? The short answer is, "no." Nevertheless, this is the version you get in all the downloadable human genome sequence databases.
If you go to the RefSeq entry for the predicted mRNA sequence of isoform 1 [NM_001159287] this is what you see ....
CCDS Note: This CCDS represents a TPI variant that uses an upstream promoter compared to the CCDS8566.1 representation. Data in PMIDs 4022011, 2925688, 2243103 and 10575546 support the presence of the internal promoter used by the CCDS8566.1 variant. The use of the upstream promoter is supported by human transcript data, including M10036.1, AL517115.3 and DB444195.1, as well as homologous transcripts. This longer transcript also uses an upstream start codon, resulting in an isoform that is 37 aa longer at the N-terminus compared to the CCDS8566.1 isoform. The sequence encoding the longer N-terminus is conserved in most mammalian species.What this means is that curators have included isoform 1 in the databases because RNAs from an upstream promoter have been sequenced. The longer version of the protein is predicted on the grounds that the first start codon (methionine codon) in a mature mRNA will be utilized. As far as I can tell, the only evidence for the biological relevance of this prediction is the fact that the sequence of the 37 predicted N-terminal amino acids is similar in most (but not all?) mammals.
If there was evidence that this protein is biologically relevant it would be mentioned here. Contrast this with the entry for isoform 2—the common version that we know is relevant [NM_000365.5].
Transcript Variant: This variant encodes the predominant isoform.So, we're left with a weird situation where the "canonical" protein sequence of the human triose phosphate isomerase gene is not the common sequence and may not even be expressed! Anyone looking for the size and sequence of the human triose phosphate isomerase enzyme will be misled into thinking that the longer, larger, version is the normal protein.
CCDS Note: This CCDS represents a TPI variant that uses an internal promoter compared to the CCDS53740.1 representation. Data in PMIDs 4022011, 2925688, 2243103 and 10575546 support the presence of the internal promoter used by this variant. The resulting isoform is 37aa shorter at the N-terminus compared to the CCDS53740.1 isoform. N-terminal sequencing in PMIDs 9150946 and 9150948 supports the existence of the shorter isoform in vivo.
This is a common problem with sequence databases because the curators and annotators don't have time to thoroughly search all the biochemical literature. They have to make decisions that are largely based on the quality of sequence data in the databases and on common sense. This has worked pretty well in eliminating most transcript variants but some of them slip through the cracks. I have no idea why isoform 3 is still thought to be important enough to reference in RefSeq.
This result—curating of so-called "alternative transcripts"—is not widely known nor appreciated. We still see scientists promoting the idea that most human protein-coding genes will produce multiple protein isoforms. For example,
Alternative pre-mRNA splicing (AS) allows a single gene to generate more than one mature mRNA species through non-uniform utilization of exonic and intronic sequences. Many multiexon transcripts in higher eukaryotes undergo AS. It is currently thought that this form of regulation effectively quadruples the number of protein isoforms compared with the number of their encoding genes in mammalian genomes.This is from a review published just a few days ago (Aug. 15, 2016) in a respectable journal (Yap and Makeyev, 2016). It is extremely misleading. The idea that the average protein-coding gene could produce four different biologically functional isoforms is ridiculous. I've chosen just one example—the triose phosphate isomerase gene—to illustrated this point but I could have picked any one of hundreds of other well-studied genes in fundamental metabolic pathways. When the structure and function of the protein product is known, the predicted versions from so-called "alternative" splice variants make no sense.
See...
The Frequency of Alternative Splicing
Two Examples of "Alternative Splicing"
Making Sense in Biology
A Challenge to Fans of Alternative Splicing
Let's look at the so-called "alternative splicing"2 databases to see examples of transcripts that have been rejected by the RefSeq curators. The point I'm making is that the majority of these extra transcripts are so nonsensical that RefSeq curators have decided to ignore them. They are undoubtedly due to splicing errors or sequencing errors and that's why they have been eliminated from RefSeq. As you look at those variants, try to imagine a situation where one of the most conserved enzymes in a fundamental pathway would need to have weird variants that couldn't possibly assemble into an active dimer.
Here are the predictions of "alternative splicing" in the human TPI1 gene ....
The Human-transcriptome DataBase for Alternative Splicing (H-DBAS) includes four different transcripts [HIX0010385]. The top one in the figure (HIT000033038) is the correct mRNA and the three below it whose names begin with "HIT" are the variants included in this database. The next three, whose names begin with "NM" or "NR" are the RefSeq transcripts. This is as close to being the "official" version as you can get. Note that NM_000365 is the correct transcript and it's identical to HIT000033038 in the H-DBAS database. The bottom three variants are from the Ensembl database. The bottom one is the correct version.
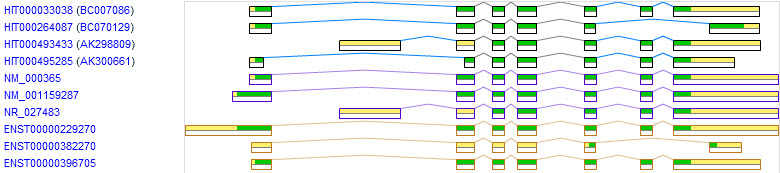
Counting the correct version, there are seven different processed transcripts and no two databases agree on all entries. As you can see below, there are dozens of other variants that have been identified but most of them have been rejected or ignored by the annotated databases such as RefSeq and Ensembl. I assume this is because they are presumed to be artifacts or splicing errors. That makes a lot sense. However, as I said above, even the ones that are included in RefSeq and Ensembl look like to me like variants that are not biologically relevant.
The Alternative Splicing Gallery (asg) shows 52 transcript variants [ENSG00000111669].

According to the ECgene, the human TPI1 gene produces 34 different transcript variants encoding 13 distinct proteins [EC gene search for TPI1].

This is what the raw data looks like. Based on "evidence" like this, many scientists conclude that the average human gene produces multiple biologically relevant protein isoforms for each gene.
1. I found one report of different variants in mouse sperm. This included detection of different proteins of higher molecular weight than the normal version.
2. Just because a splice variant can be detected does not mean that it is functional. It could be a splicing error. "Alternative splicing" should be restricted to a phenomenon that's known to be biologically relevant in producing different function products. A simple collection of all transcripts, including mistakes, is just a collection of transcripts and processed transcripts. It may or may not include genuine examples of alternative splicing.
Image Credit: The first two figures are from: Moran, L.A., Horton, H.R., Scrimgeour, K.G., and Perry, M.D. (2012) Principles of Biochemistry 5th ed., Pearson Education Inc. page 175 [Pearson: Principles of Biochemistry 5/E]
Yap, K., and Makeyev, E. V. (2016) Functional impact of splice isoform diversity in individual cells. Biochemical Society Transactions, 44:1079-1085. [doi: 10.1042/BST20160103]
60 comments :
Looks like the APPRIS database correctly annotates the second version as the principal isoform:
http://appris.bioinfo.cnio.es/#/database/id/homo_sapiens/ENSG00000111669?as=hg38&sc=ensembl
I came across this database while googling for papers on identifying principal isoforms for a project of mine, but haven't checked how reliable it is yet. This is a good sign.
Still, there are a few human genes that do have genuine alternative splicing. The only one I know anything about is MYC, sometimes called c-myc, which has two isoforms with different functions. So alternative splicing is a little bit real.
John
" Still, there are a few human genes that do have genuine alternative splicing. The only one I know anything about is MYC, sometimes called c-myc, which has two isoforms with different functions. So alternative splicing is a little bit real."
How would you explain the MIt and UT papers I sent you showing increased splicing activity in vertebrates that reaches a maximum level in primates. Based on Larry's thesis that would mean that splicing errors are becoming more frequent in primates.
I don't recall you sending me any such papers.
There are at least a dozen well-characterized examples of genuine alternative splicing in humans. The most famous example is IgM where alternative splicing is responsible for producing secreted and membrane-bound versions.
The issue isn't about the EXISTENCE of alternative splicing, it's about how many genes produce different variants and how many variants are produced.
There is absolutely no doubt about the fact that most variant transcripts are due to artifacts and splicing errors.
I will re send on email.
I have it. Now make my life easy. Quote the passages in each paper that show there is "increased splicing activity in vertebrates that reaches a maximum level in primates", and provide page and column for each.
What about isoform 1, the version with the extra 37 amino acid residues? Is there any evidence that this protein actually exists in a biologically relevant form? The short answer is, "no."
Probably you are more concerned with alternative splicing in this post, but with respect to alternative start codons:
even if this form was expressed with some detectable frequency, I wouldn't bet any money on the possibility that this N-terminal extra 37 amino acids alters the activity of the enzyme in any physiologically-significant way. It could of course, but I would initially suspect that it is exactly the same enzyme with an inconsequential N-terminal extension, until demonstrated otherwise.
Do you have a citation to those papers, so the rest of us can play along?
There seems to be only one paper, plus an irrelevant press release. This is the paper:
Barbosa-Morais NL. 2012. The Evolutionary Landscape of Alternative Splicing in Vertebrate Species. Science 338:1587-1593.
There are two more I will send them again.
Neither of the additional papers seems relevant to your major claim, which if I may remind you is that there is "increased splicing activity in vertebrates that reaches a maximum level in primates".
John
"How species with similar repertoires of protein-coding genes differ so markedly at the phenotypic level is poorly understood. By comparing organ transcriptomes from vertebrate species spanning ~350 million years of evolution, we observed significant differences in alternative splicing complexity between vertebrate lineages, with the highest complexity in primates. "
Here is the papers claim. There is also a chart of splicing activity showing relative frequency between several different vertebrates as compared to humans.
The other papers do show a high level of AS in humans and one compares mouse rodents and overall mammals with increased frequency.
lutesuite
The most relevant paper is paywalled. If you give me your email address I will send you a PDF.
Bill, when you quote, please state what you are quoting from. When you make a claim about what a paper says, please quote. Try to get all elements in place before posting.
It's OK, Bill. I have institutional access.
That's a pretty complicated paper. I'm impressed that you understand it so well. And better than John Harshman, no less.
lutesuite
Science
www.sciencemag.org
Science 21 December 2012:
Vol. 338 no. 6114 pp. 1587-1593 DOI: 10.1126/science.1230612
Uh, right, Bill. John already posted the reference, and I've already downloaded the paper. How do you think I knew it was complicated, without having read it?
John asked you to do some things. Quit wasting your time with me, and get working on that.
"Quit wasting your time with me,"
Good advise.
I think the discussion could also be put into the broader context of the (perhaps settled) Introns Early vs Late debate. Many evolutionary biologists would likely argue that the origination of splicing had nothing to do with generating alternative isoforms of a gene, but instead grew out of the necessity of dealing with invading retro elements or self splicing intronic elements. Eugene Koonin's paper "The origin of introns and their role in eukaryogenesis: a compromise solution to the introns-early versus introns-late debate?" puts things nicely into perspective.
There are also many papers noting the inverse correlation with intron number/length and recombination rate within a genome, and effective population size between organisms.
Hi Laurence, you mentioned that TPI1 is highly conserved, but have you looked at whether the position and phase of introns in TPI1 orthologs are conserved?
John
This quote from the UT paper supports my initial claim that alternative splicing complexity (frequency) increases among vertebrates lineages with the most complexity in primates.
"How species with similar repertoires of protein-coding genes differ so markedly at the phenotypic level is poorly understood. By comparing organ transcriptomes from vertebrate species spanning ~350 million years of evolution, we observed significant differences in alternative splicing complexity between vertebrate lineages, with the highest complexity in primates. "
I think the tone could be a little friendlier guys. What's the point in commenting if it's just to beat down on someone.
Having read the relevant section of the paper and sup. it looks like the statement from the Barbosa-Morais et al paper quoted by Bill Cole stacks up. Figure 1A clearly shows an increased rate of alternative splicing (exon skipping) in primates with the analysis restricted to homologous exons. The sup. details the extensive lengths they went to go to making sure this wasn't due to some other confounding bias. My only remaining gripe with the method they used is that the minimal expression threshold for an exon to be included in the analysis is quite low and they don't show the relationship between % exon skipping and expression level in the supplementary figures.
So if primates do indeed show a higher level of exon skipping, does this indicate less precise splicing in primates?
Unfortunately, the version of the paper Bill sent me shows all the figures too small to be intelligible, and I'm not allowed to enlarge them without a subscription to Science. The supplementary information is better.
I would certainly like to know how the frequencies of alternative splicings compare. Does the main isoform always dominate? If not, that would be evidence that something more than random error is happening. I'd also like to see a less biased taxon sample. You can't really say that primates have more alternative splicing than other mammals, when the primates are all old world monkeys and the only other placental is "the mouse". Nor would I consider a chicken, a lizard, and a frog to adequately sample other vertebrates. But it's interesting, and I don't understand the result so far.
Splice variants of the human triose phosphate isomerase gene: is alternative splicing real?
Yes Larry. It's real. Any attempt of yours from now on to water-down this fact by saying how prevalent the alternative splicing is, it's just not going to cut is as Harshman and other pointed it out. To prevail, you would have to change the tile of your blog to:
"Splice variants of the human triose phosphate isomerase gene: is alternative splicing prevalent?"
But then, you would defeat the subtle purpose of your blog in the first place.
If the purpose of the blog is to insinuate alternative splicing isn't real, why does Larry write in the comments, as a response to the very first post: "There are at least a dozen well-characterized examples of genuine alternative splicing in humans. The most famous example is IgM where alternative splicing is responsible for producing secreted and membrane-bound versions."
Cruglers, is idiocy something you practice or does it come naturally for you? You're so good at it.
I wonder which kind of evidence there really is for all those TPI mRNAs to be translated. At least for the two transcripts that start with a long non-translated exon followed by a second non-translated exon one gets the impression that the first ATG (I refuse to say initiation codon here) within the next exon that is in frame with the ORF of the canonical cds was cherry-picked although other out of frame ATGs were availbale in what is supposed a un-commonly long 5'-UTR. I didn't check it but it may well be that these transcripst are prone to NMD due to the existance of PTCs > 50 nt upstream of a splice donor site that would occur if other ATGs were used instead of the one chosen. IIRC, some of the research that led to the elucidation of the mechanisms underlying NMD has actually been done with the TPI gene.
There are many examples of functional products produced by alternative splicing. Even enzymes without an active site can still have scaffolding or regulatory function. The guy I mostly deal with, caspase-8, seems to do that a lot. Some of the very short isoforms have been shown to play a role in cell migration, for example, rather than execute cell death. Prevalence is another matter, though. Some splice variants may be very rare and are only found in certain cells/tissues under particular conditions. It is a bit of a nuisance that many databases use the longest form of a protein as the canonical, even though that's often a rare splice variant. As for the structural databases, many structural biologists and biochemists tend to use the same clone of a gene that someone once made. The literature is quite biased that way. Cloning used to be quite a job, but now it's so easy that splice variants are getting more attention. They do some interesting and unexpected things sometimes!
I don't know why Creationists are so keen to latch on to every novel piece of information as if it were a major Paradigm Shift. Alternative splicing, epigenetics, ENCODE, glycan codes, structural regulation; all are waggled gleefully in the face of the scientist as if they must fatally undermine their most cherished beliefs regarding how biology works.
And if the scientist happens to be skeptical of the validity of the paradigm shift case ... "shake harder, boy!".
Hi John, happy to send you another PDF of the main paper if you want?
Point taken on the taxon samples, though considering they were generating all the samples themselves I guess there had to a be a limit on the number of species they could include. Unless I missed it, in terms of comparing between species, I don't think they go beyond saying there is variation between vertebrates and primates show the highest level of AS.
SF8 breaks down F1C which shows the clustering of samples by the exon splicing frequencies (PSI). Here they are shown for different ranges of PSI. In SF1A the primate brain samples cluster together much better when the PSI range is 45-55% compared to 25-75%. This could just be a quirk of the reduced amount of data used in the clustering but my reading of this is that AS at exons with mid-frequency is more likely to be truly biologically relevant, as you suggest.
SF9 also all answers some of my concerns with regards to the thresholds for minimal read coverage.
Is the AS frequency correlated with specific tissues?
What I mean is, are genes in for example skin cells alternatively spliced at a lower frequency than the same genes in brain cells?
If so, does this also extend to other orders? Would the same be true for chickens, frogs and so on?
The paper is difficult to understand but I think it requires a high quality genome sequence. That limits the number of species that can be used. The human and mouse genome sequences are the only "finished" sequences. as far as I konw They are probably the only ones with a nearly complete euchromatic sequence. I don't think the frog and chicken sequences are very good.
Back in the late 1960s we learned that there were many more transcipts in brain tissue and in testes. Later on it became apparent that there were also many more examples of unusual processing events. Many of us have come to believe that transcrption and splicing are much more sloppy and error-prone in those tissues.
BTW, the paper we are discussing is not actually about "alternative splicing" in the traditional sense of the word. It's about the appearance of processed transcripts that include predicted splice sites. These MAY be examples of alternative splicing but all available data strongly suggests that most of them are splicing errors or artifacts.
The paper presents evidence that such errors might be more common in primates than in other species. I asked my colleagues at the University of Toronto to show me the so-called "alternative transcriots" they detected for some common genes like TPI1 and the RNA polymerase subunits so I could see what the raw data looked like. They declined my request.
@Larry. As I understand it their analysis is limited to orthologous exons so I don't think it matters that the frog and chicken annotations are incomplete, except that it reduces the number of exons they can study. Of course, you're right that this also limits the available species.
Have you got any reference regarding more error-prone transcription/splicing in the brain/testes. Would be very interested to read. Do you have any theory as to why this would be? I know that in the testes there have been a bunch of other transcriptional oddities observed (e.g high abundance of 5'-half tRNAs etc) which disrupt transcription and co/post-transcriptional processes so this could be an explanation?
I'm not sure why the events in the paper in question wouldn't be considered as AS? They're looking specifically at exon skipping. Does this not count?
It's a shame your colleagues wouldn't share their raw data with you. My understanding is that they don't have alternative transcripts. What they have are reads supporting particular splicing events so the raw data isn't going to look very convincing. Personally, I think a lot of the annotations will need cleaning up when we move onto longer read technologies, Oxford Nanopore being the best hope right now. Then we will be mostly generating full length reads rather than shotgunning the transcriptome. illumina (and other short reads) are just not long enough to properly annotate at the isoform level with any confidence. There's one hell of an automated annotation clean-up to come...
@Mikkel. I don't think they address this directly in the way you ask. However, the PCA (Sup. Fig5C) does suggest a reasonable proportion of the variability in this form of AS (~15%) is due to consistent tissue-specific events across 4 vertebrates. Of course, just because they're consistent doesn't mean they're functional.
A 2004 article on 144 alternatively spliced human protein isoforms from SWISS-PROT V.41 whose mRNA transcripts contain premature-termination codons mentioned 7 splice variants of Casp8-mRNA containing PTCs. Thus, I wonder how many isoforms beside Casp-8 and Casp8L have been detected by Western blottting.
From another paper:
"A number of isoforms of caspase-8 have been described at the mRNA level (9, 10). Our mAb against the three major domains of FLICE (the prodomain and the active subunits p18 and p10) enabled us to test which of the reported caspase-8 isoforms were actually expressedin vivo. To this end several cell lines representing different tissues were tested for FLICE expression by Western blotting using the N2, C15, and C5 anti-FLICE mAbs (Fig.2). Surprisingly, all three antibodies detected only two bands of 55 and 53 kDa of equal intensity in almost all cells. Other caspase-8 isoforms were undetectable."
Larry, totally off topic but I would be interested in your opinion of VJ Torley's criticism of Doug Axe's latest book. It was originally posted at UD but Barry had it removed, along with all references to it in other comment threads. One warning. In typical VJT fashion, his review is longer than the book he is reviewing.
http://www.angelfire.com/linux/vjtorley/axe.html
My anti-malware program won't allow access to that website.
I haven't read Axe's book and I'm not planning to read it any time in the forseeable future.
I've found a cached version of the review that works for me. Not that I necessarily recommend anyone read it. I haven't.
http://tinyurl.com/zgdxmx6
Actually, while I didn't read the whole review, I did skim the conclusion, and I can see why Barry wants to supress this. Torley pretty well admits that the entire ID enterprise is based on a flawed premise and calls for a complete intellectual overhaul, though he tries to word that in as positive terms as possible.
I predict he will soon be following the example of Luskin, Dembski, Sal Cordova, and others who have dissociated themselves from the ID movement. That is, if Barry doesn't simply purge him outright.
Conversely, Ensemble and NCBI appear to underestimate the number of relevant transcripts for many Ig genes.
They only have a single (secreted) isoform for IGHA1/2, IGHE, and IGHG1/2/3/4 but these should also have a membrane-bound isoform with an extra exon 1-3kb downstream.
(IGHM and IGHD are listed with both isoforms though.)
Sal seems to be copying from AIG recently, or similar YEC sources. Not sure how that is an improvement over uncommondescent. I think they banned him. Come to think of it, Sal used to have OP priveleges at UD.
Meanwhile VJ Torley seems to have evicerated Axe's Undeniable and briefly published the review at UD. Who could have predicted trouble?
Does anybody know if it even dimerizes? Because I'm wondering in which direction the N-termini point.
"There are many examples of functional products produced by alternative splicing." How much is "many" and how do you know?
Big Brother has made Winston Torley an unperson. He has been airbrushed out of all photos showing he once existed.
Lutesuite, thanks for the link. Fascinating. Torley says that "the book contains numerous mathematical, scientific and philosophical blunders, which a sharp-eyed critic could easily spot." Of course Axe must be protected, so Torley says "I do not hold Dr. Axe responsible for most of the errors in his book.... however, Dr. Axe sent his manuscript out (in whole or part) to no less than fifteen people (mathematicians, scientists, philosophers and writers), soliciting their comments on his book. I won’t name them here, as I have no wish to publicly embarrass them, but they are listed in the author’s Acknowledgments (pp. 275-276). It is these people whom I hold responsible for the errors in Dr. Axe’s book."
Who are these fifteen "mathematicians, scientists, philosophers and writers" that Torley blames? If you go to Amazon, you can use their "Look Inside" function to read p. 275.
Axe, p.275-6: "I deeply appreciate the many people who took their time to read the manuscript, in part on in whole... Titus Kennedy, Casey Luskin, George Montanez, Steve Zelt, Steve Fuller, Bill Dembski, Jonathan Wells, Rebecca Keller, Mariclair Reeves, Jacob Koch, Grant Gates, Ann Gauger, Fraser Ratzlaff, Chuck Wallace, and Eric Garcia are all to be thanked for this"
These people are on Torley's shit list. Of course, Luskin, Dembski, Wells, Gauger are well known to us. With the exception of Steve Fuller, I don't know the others. Fuller is the sociologist of science who appeared in "Expelled" going on about abortion and whatever.
Titus Kennedy:
https://www.biola.edu/directory/people/53a9e1f77275626fe4af1200
George Montanez:
http://dblp.uni-trier.de/pers/hd/m/Montanez:George_D=
Steve Zelt:
http://stevezelt.blogspot.com/search?updated-max=2010-10-03T06:58:00-07:00&max-results=7&start=7&by-date=false
Rebecca Keller:
https://en.wikipedia.org/wiki/Rebecca_W._Keller
https://www.amazon.com/Rebecca-W.-Keller/e/B002LKY058
Mariclair Reeves:
http://www.biologicinstitute.org/people (scroll down)
https://www.researchgate.net/profile/Mariclair_Reeves/publications
Eric Garcia is the "Vice President" of the discotoot:
http://www.discovery.org/about/contact
The Wikipedia discotoot page also lists him as the "Vice President":
https://en.wikipedia.org/wiki/Discovery_Institute
Garcia apparently used to be the treasurer:
http://lippard.blogspot.com/2007/01/creationist-finances-discovery.html
Fraser Ratzlaff works for a christian non-profit called Children of the Nations:
https://www.linkedin.com/in/fraser-ratzlaff-287440aa
Ratzlaff apparently attends "The Downtown Church":
http://www.thedowntownchurch.us/downtown-news/author/u/21/fraser--ratzlaff
Douglas Axe is an "Elder" in that church:
http://www.thedowntownchurch.us/about/our-leaders
At "The Downtown Church" website, click on "About" and then on "Our Beliefs".
Bonus tard: Interview of Douglas Axe:
http://www.wataugademocrat.com/mountaintimes/interview-douglas-axe-explains-life-s-origins-through-design-intuition/article_1c3865b8-08de-50c1-b7a5-b431145adcfd.html
I didn't find much, if anything, on the others. If anyone finds or already knows that anything above is incorrect, please let me know.
Excellent google fu, TWT. So Axe is asking the people who work at his church to read his book. Kennedy works at the Bible Institute of Los Angeles (aka BIOLA).
Eric Garcia I had heard of before, but I forget when or where.
I am reading Torley's review of Axe, and it's unintentionally hilarious. Torley is attempting to improve Axe's notion of "functional coherence" (which is just Behe's irreducible complexity worded more vaguely) by writing things like:
Dr. Axe’s Universal Design Intuition would be much more persuasive if it were formulated as follows: “If we find a level of functional coherence in living organisms which surpasses anything which our top scientists can create, then we should conclude that the systems displaying this level of functional coherence were designed, and that the accidental invention of these systems is fantastically improbable and therefore physically impossible.”
Translation: 'We have never observed anything like this being designed by any intelligent being, therefore this must have been designed by an intelligent being'
Human inventions don’t even come close to the level of skill it embodies. Design is the obvious and sensible inference to make, barring an empirical demonstration that Nature’s powers of inventiveness far surpass our own.
'We have never observed anything like this being designed by any intelligent being, therefore this must have been designed by an intelligent being' over and over and over.
And Torley is calling out Axe's logic errors!
That is absolutely astonishing, Diogenes. The "reasoning" here is to observe "functional coherence" in things that have been designed by intelligent agent, and yet when this same "functional coherence" is observed in things whose complexity is beyond the design capabilities of any known intelligent agent, the conclusion drawn is that it must have been designed by such an agent.
Torley needs to demand a refund from whatever philosophy school taught him to think like that.
In the passage below, Torley makes a point that must have driven the UDites insane. I can easily see how this bit would make ambulance chasin' Arrington crazy. He challenges Axe's claim that genomes are the same as messages written in human languages (Axe's analogy is boiling alphabet soup, and creating a patent for an invention.) Torley says that's a bad analogy because there's a difference between "useful" and "meaningful", like human language, and biological structures can be useful without being meaningful. And the odds of evolution creating something useful are much greater than the odds of creating something meaningful.
In this passage, Torley sounds a lot like... me, saying what basically what I've been saying for a long time. (Forgive me for wondering if Torley has been reading my comments.)
In order for an accidentally generated string of letters to convey a meaningful message, it needs to satisfy three very stringent conditions, each more difficult than the last: first, the letters need to be arranged into meaningful words; second, the sequence of words has to conform to the rules of syntax; and finally, the sequence of words has to make sense at the semantic level: in other words, it needs to express a meaningful proposition. For a string of letters generated at random to meet all of these conditions would indeed be fantastically improbable. But here’s the thing: living things don’t need to satisfy any of these conditions. Yes, it is true that all living things possess a genetic code. But it is quite impossible for this code to generate anything like nonsense words like “sdfuiop”, and additionally, there is nothing in the genome which is remotely comparable to the rules of syntax, let alone the semantics of a meaningful proposition. The sequence of amino acids in a protein needs to do just one thing: it needs to fold up into a shape that can perform a biologically useful task. And that’s it. Generating something useful by chance – especially something with enough useful functions to be called alive – is a pretty tall order, but because living things lack the extra dimensions of richness found in messages that carry a semantic meaning, they’re going to be a lot easier to generate by chance than (say) instruction manuals or cook books. Hence it may turn out that creating life by chance is extremely improbable, but not fantastically improbable. In practical terms, that means that given enough time, life just might arise.
The bolded material would absolutely drive the UDites crazy. I can easily imagine how Ambulance Chaser, BatShitCrazy and He Who Shall Not Be Named would respond to the above. They'd blow their gaskets.
(Forgive me for wondering if Torley has been reading my comments.)
Well, it wouldn't be the first time he used knowledge gained from folks here at Sandwalk in one of his articles, though he sometimes needs a bit of prodding to provide attribution:
http://www.rationalskepticism.org/post2369174.html
I'm also reading the "Our Beliefs" section of Doug Axe's church, which is also attended by Ratzlaff, who read Axe's book.
The Bible is our bottom line. It shapes everything about our lives and our theology.
Yeah no shit.
We believe the Bible is the Word of God, verbally inspired by the Holy Spirit, and without error in the original manuscripts. It is authoritative over all matters of life. Our daily responsibility is to yield to God's Word.
I'm shocked. Who could possibly have guessed they decided on the correct answer ahead of time.
God who creates (Creation and Man's Fall)
We believe God is the creator and sustainer of the universe and all that it contains. He created everything for His enjoyment and glory. God created man uniquely in His image...
So, totally open-minded about creation vs. evolution as usual. (Remember, if you catch the creationists making false statements, they always respond by saying, "I'm just askin' questions!" Yeah, they're asking questions about a subject where only one answer is permissible.)
Bonus question: if God "created everything", what do you use as a negative control when testing your hypothesis "God created life"? If God created everything, your design detector would be like a geiger counter that clicks when pointed at any object. How can you verify that your detector works?
And this:
The church is to be led by spiritually qualifed men, under the leadership of Jesus.
Sorry ladies! You can make cupcakes. And:
We believe in the resurrection of men, the final judgment, the eternal joy of the righteous, and the endless suffering of the wicked in hell.
Our God's love is unconditional! Think what we tell you to think or he'll set you on fire forever.
But back to Torley's review. One interesting passage is where Torley invokes the "snowflake" counter-argument to claims that natural processes can't create complex things. Of course we have invoked the snowflake counter-argument for many years. They say, "Natural processes can't create a complex thing!" and we reply "If true, that would mean snowflakes were made one by one by snow fairies, instead of natural processes."
The snowflake argument drives creationists cuckoo. They hate it. But Torley brings it up:
Perhaps it might be suggested that the [Axe's] Universal Design Intuition applies only to highly complex arrangements of matter, rather than low-complexity structures such as raindrops and diamonds (which have a fairly regular, face-centered cubic crystal structure). Very well, then: but what about individual snowflakes? While making snow isn’t too difficult, there’s no doubt that a lot of knowledge would be required if I wanted to make a perfect replica of a particular snowflake. Should I then conclude that each snowflake was designed?
Smartly, Torley limits his claim to the large amount of information that would be required to re-create one particular snowflake, which is not the same thing as saying that the rules for creating any old snowflake are super-complex. (For you math nerds, Torley is gesturing toward the difference between the Kalmogorov-Chaitin complexity of the description of the molecular structure of one particular snowfake, vs. the simplicity of the laws of physics that make snowflakes in general.)
However, Torley then appears to dismiss the snowflake, on the grounds that it does not have "function", while biological things have function:
... Axe propounds his core argument in support of the Universal Design Intuition: “Functional coherence makes accidental invention fantastically improbable and therefore physically impossible.” Inventions, we are told, “exhibit an organized, functional coherence that can only come from deliberate, intelligent action” (p. 160). Functional coherence is the reason why “inventions can’t happen by accident” (p. 160). This formulation of the Universal Design Intuition is a lot sharper than the initial one, because it shifts the focus to a well-defined property (functional coherence), which means that we need not worry about snowflakes, diamonds or rain, as none of them exhibit this singular trait.
(I would strongly disagree that Axe's "functional coherence" is well-defined.) But note that now Torley, having invoked the snowflake, dismisses it, on the grounds that it isn't functional.
Of course we could respond that snowflakes have many functions: to be beautiful, to be skied on, to stick together and make snowmen, etc. But more on function in a moment.
Torley continues: "In Dembskian terminology, Axe has made a clever move here: he has quietly dispensed with the problematic notion of specified complexity (which could apply even to arrangements of pebbles), and identified functional specified complex information (FCSI) as the hallmark of intelligent design..."
Certainly the claim that "arrangements of pebbles" can have Dembski's CSI would infuriate many of Dembski's acolytes!
The only difference between Dembski's CSI and the FIASCO promoted by the denizens of UD, like He Who Shall Not Be Named, is that FIASCO has an "F" for function. That's it.
So Torley pins his hopes on the "F" for function in FIASCO that it will dismiss counter-arguments like snowflakes, but of course some of our counter-arguments have real functions.
Consider natural bridges and arches formed by erosion. They have Behe's irreducibly complexity (IC) in the sense that, if you cut out a big chunk of a natural bridge, it would collapse and no longer perform it's function. And they have real functions: many have roads or paths that lead over streams and rivers, and they have the same function as man-made bridges. So they have the "F" in FIASCO.
One could also mention irreducibly complex natural structures like the natural nuclear reactor found in Gabon. It had a negative-feedback mechanism to keep its neutron flux within a moderate range to generate moderate heat for many years, and that mechanism was Irreducibly Complex (IC) by Behe's criterion. And it performed the same function as man-made nuclear reactors, so it has the "F" in FIASCO.
So, yes, natural processes create structures that have both Dembski's CSI, and Behe's Irreducible Complexity, and the "functional" FIASCO preferred by the denizens of UD.
Hey Larry, you might be interested that Torley is citing anonymous profs who cite... you. Torley's three profs that he consults are called "Professors A, B, and C" (C doesn't want to be anonymous, it's James Tour. A is a Christian "Darwinist" while B is a Christian who "has strong doubts regarding the possibility of abiogenesis, but adheres to the neutral theory of evolution".)
But interestingly, in a critique of Axe's "big numbers" argument that protein A can never evolve into protein B, Torley writes:
Professor B, however, was harshly critical of Axe’s argument. All Axe had done, he said, was to take two related proteins (A and B), and tweak them very slightly, in an attempt to change A into B. That didn’t work, so Axe had leapt to the unwarranted conclusion that there was no good path from A to B, and that all proteins are isolated in function, when in reality, he had not proven this at all. Professor B argued that this inference was clearly mistaken, because Axe had not even tried a moderate number of paths from protein A to protein B – let alone all possible paths. Professor B added that most scientists believe that there was an ancestral protein C from which A and B could be easily derived, and that this protein would have performed the functions of both protein A and protein B. He faulted Axe for making no attempt to identify the ancestral protein C, and change C into A and into B.
Professor B thought Dr. Axe was extending his work far beyond what the data currently indicates. He contended that Dr. Axe was over-interpreting his data, and that he wasn’t test the true evolutionary model in the correct fashion, but was attacking a straw man instead. Tellingly, Professor B endorsed Dr. Larry Moran’s critiques of Axe’s work (see here and here).
The cited blog posts are pretty old:
Douglas Axe on Protein Evolution and Magic Numbers (Oct. 18, 2012)
The Evolution of Enzymes from Promiscuous Precursors (July 26, 2012)
It seems like it would be relatively straightforward to test via western blot or something. In vitro translation followed by some mixing to allow for dimerization and you should be able to see two bands.
Post a Comment