I've been writing some stuff about epigenetics so I've been reading papers on how to define the term [What the heck is epigenetics? ]. Turns out there's no universal definition but I discovered that scientists who write about epigenetics are passionate believers in epigenetics no matter how you define it. Surprisingly (not!), there seems to be a correlation between belief in epigenetics and other misconceptions such as the classic misunderstanding of the Central Dogma of Molecular Biology and rejection of junk DNA [The Extraordinary Human Epigenome]
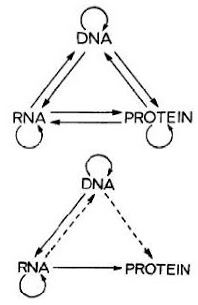
Here's an illustraton of this correlation from the introduction to a special issue on epigenetics in Philosophical Transactions B.
Ganesan, A. (2018) Epigenetics: the first 25 centuries, Philosophical Transactions B. 373: 20170067. [doi: 10.1098/rstb.2017.0067]
Epigenetics is a natural progression of genetics as it aims to understand how genes and other heritable elements are regulated in eukaryotic organisms. The history of epigenetics is briefly reviewed, together with the key issues in the field today. This themed issue brings together a diverse collection of interdisciplinary reviews and research articles that showcase the tremendous recent advances in epigenetic chemical biology and translational research into epigenetic drug discovery.
In addition to the misconceptions, the text (see below) emphasizes the heritable nature of epigenetic phenomena. This idea of heritablity seems to be a dominant theme among epigenetic believers.
A central dogma became popular in biology that equates life with the sequence DNA → RNA → protein. While the central dogma is fundamentally correct, it is a reductionist statement and clearly there are additional layers of subtlety in ‘how’ it is accomplished. Not surprisingly, the answers have turned out to be far more complex than originally imagined, and we are discovering that the phenotypic diversity of life on Earth is mirrored by an equal diversity of hereditary processes at the molecular level. This lies at the heart of modern day epigenetics, which is classically defined as the study of heritable changes in phenotype that occur without an underlying change in genome sequence. The central dogma's focus on genes obscures the fact that much of the genome does not code for genes and indeed such regions were derogatively lumped together as ‘junk DNA’. In fact, these non-coding regions increase in proportion as we climb up the evolutionary tree and clearly play a critical role in defining what makes us human compared with other species.
At the risk of bearting a dead horse, I'd like to point out that the author is wrong about the Central Dogma and wrong about junk DNA. He's right about the heritablitly of some epigenetic phenomena such as methylation of DNA but that fact has been known for almost five decades and so far it hasn't caused a noticable paradigm shift, unless I missed it [Restriction, Modification, and Epigenetics].