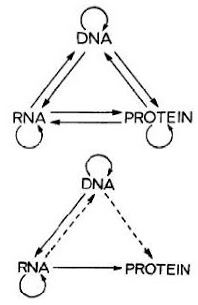
The Central Dogma of molecular biology states ...
... once (sequential) information has passed into protein it cannot get out again (F.H.C. Crick, 1958).
The central dogma of molecular biology deals with the detailed residue-by-residue transfer of sequential information. It states that such information cannot be transferred from protein to either protein or nucleic acid (F.H.C. Crick, 1970).
This is not difficult to understand since Francis Crick made it very clear in his original 1958 paper and again in his 1970 paper in Nature [see Basic Concepts: The Central Dogma of Molecular Biology]. There's nothing particularly complicated about the Central Dogma. It merely states the obvious fact that sequence information can flow from nucleic acid to protein but not the other way around.
So, why do so many scientists have trouble grasping this simple idea? Why do they continue to misinterpret the Central Dogma while quoting Crick? I seems obvious that they haven't read the paper(s) they are referencing.
I just came across another example of such ignorance and it is so outrageous that I just can't help sharing it with you. Here's a few sentences from a recent review in the 2020 issue of Annual Reviews of Genomics and Human Genetics (Zerbino et al., 2020).
Once the role of DNA was proven, genes became physical components. Protein-coding genes could be characterized by the genetic code, which was determined in 1965, and could thus be defined by the open reading frames (ORFs). However, exceptions to Francis Crick's central dogma of genes as blueprints for protein synthesis (Crick, 1958) were already being uncovered: first tRNA and rRNA and then a broad variety of noncoding RNAs.
I can't imagine what the authors were thinking when they wrote this. If the Central Dogma actually said that the only role for genes was to make proteins then surely the discovery of tRNA and rRNA would have refuted the Central Dogma and relegated it to the dustbin of history. So why bother even mentioning it in 2020?
Crick, F.H.C. (1958) On protein synthesis. Symp. Soc. Exp. Biol. XII:138-163. [PDF]
Crick, F. (1970) Central Dogma of Molecular Biology. Nature 227, 561-563. [PDF file]
Zerbino, D.R., Frankish, A. and Flicek, P. (2020) "Progress, Challenges, and Surprises in Annotating the Human Genome." Annual review of genomics and human genetics 21:55-79. [doi: 10.1146/annurev-genom-121119-083418]
8 comments :
For some reason I was expecting you to mention a case of ambiguity with respect to post-translational modification of proteins by other proteins(or editing of nucleic acid sequences by proteins) as that's usually what so-called "exceptions" to the central dogma are claimed to be.
But no, this was worse than I had even dared to dream.
Hi Larry Moran,
the equivalent ultimately goes back to a mistake made by James D. Watson in the first edition of his “Molecular Biology of the Gene” (1965)...
Cheers,
Lamarck
If you had read my 2007 post this is what you would have seen ...
"Unfortunately, there’s second version of the Central Dogma that’s very popular even though it’s historically incorrect. This version is the simplistic DNA → RNA → protein pathway that was published by Jim Watson in the first edition of The Molecular Biology of the Gene (Watson, 1965). Watson’s version differs from Crick’s because Watson describes the two-step (DNA → RNA and RNA → protein) pathway as the Central Dogma. It has long been known that these conflicting versions have caused confusion among students and scientists (Darden and Tabery, 2005; Thieffry, 1998). I argue that as teachers we should teach the correct version, or, at the very least, acknowledge that there are conflicting versions of the Central Dogma of Molecular Biology."
The Watson version did NOT rule out noncoding genes. In fact, Watson discusses tRNA and rRNA genes in the first edition of his book.
Is there a reason that sequence information can not be transferred from a protein to another protein or nucleic acid?
For several reasons, but mainly because of the degeneracy of the genetic code. A single amino acid in a protein can be coded by several triplets of RNA (codons), as in:
amino acid: Valine RNA codons: GTT, GTC, GTA, GTG
When you try to go back from protein to RNA, you will be confronted with a crazy amount of possible RNA sequences. Just imagine how many possible sequences there could be with a really short 200 amino acid protein.
Fukuda,
Sure, but any of those RNA sequences would be acceptable as a reverse translation, since any one of them could be translated to reproduce the same peptide. I see no physical reason why there could not be a reverse translatase, but there are several reasons why it would be difficult. First, it would have to work with a denatured protein, since in a folded protein many sites would be inaccessible. Second, a single enzyme would have to recognize all 20 amino acids; perhaps there would have to be 20 diferent enzymes, working like backwards tRNAs.
At any rate, the central dogma isn't about what's possible. It's about what we observe. There is no reverse translatase. Maybe that's because it's not possible to make one, or maybe it's just that none happened to arise.
You're missing the point of the central dogma.
Post a Comment